The concept of model and conceptual model in information science
Keywords: Conceptual model, information science, domain ontology, metadata schema, model
PhDr. Helena Kučerová, Ph.D. / Ústav informačních studií a knihovnictví FF UK v Praze (Institute of Information Studies and Librarianship, Faculty of Arts, Charles University in Prague), Filozofická fakulta Univerzity Karlovy, U Kříže 8, 158 00 Praha 5 - Jinonice
All models are wrong; some models are useful.1
George Edward Pelham Box (1919–2013)
Introduction
The creation and application of models is seen to accompany practically all types of human activities. They are involved both in subjective cognitive processes and in objective methods of scientific examination or engineering design. Models are generated within the process of artistic creation, in the course of communication activities as well as in that of practical handling. Such broad scope is clearly visible also in the field lying in the focus of interest of the information science. The Czech terminology database of library and information science (TDKIV) contains both terms designating concrete models (dummy copy, map, draft, document template etc.), and terms related to all sorts of abstract models (database model, conceptual database model, logical database model, meta-information system, relational data model, open access model etc.). As will be shown in part 3.2, also an important category of the information science can be understood as consisting of models – secondary sources and metadata, including knowledge organization systems. Thus, e. g., a catalogue can be held for a model of the library collection, the abstract or subject index for models of the book content, the bibliographic list or the profile of the library collection for models of resource sets, bibliographic data for a model of the document features, a search pattern of the document/question for a model of the contents, the search profile for a model of the user´s needs, etc.
Although it can be stated that the creation and utilization of models have been always implicitly comprised in the practice of libraries and further memory and fund oriented institutions, their explicit examination by the information science is still in its beginnings. Actually, the interest for the theoretic problems of modelling in the information science is not noted before the end of the 90ies of the 20th century, namely when the IFLA FRBR model (Functional requirements for bibliographic records) was published. Down to the present day, however, the activities have been rather directed to the application of knowledge from other domains, in particular computer science. Thus, upon superficial first sight based on the topically used terminology (conceptual model, entity-relationship model, data model), it could seem that modelling and models were not introduced to the information science before computer science. Yet a slightly more comprehensive analysis of broader theoretical and practical contexts of the creation of models can show that artefacts bearing the name of models at the present day have been created in the libraries and further memory and fund oriented institutions since times immemorial, however, without being labelled and perceived as such. This “implicit“ approach to the creation and application of models, anyway, should be replaced with explicit investigation, enabling us to form a special theory corresponding with the specific object of examination and the methods of information science. That is why this article reflects our effort to outline the directions that can be beneficial, in our opinion, for further progress of models in the information science. In accordance with the prevailing types of models in this domain we focus upon conceptual models.2
The discipline of computer science, having set out on its way to its own theory of conceptual models as early as in the 60ies of the 20th century, can serve as inspiration for the information science in this respect. In the result there is a broad knowledge base comprised in numerous contributions from conferences, articles in professional journals and scientific monographs, textbooks and handbooks, having supported the constitution of an influential stream of theoretical thought bringing inspiration and application opportunities also to other scientific disciplines. Much the same as the experts in the fields of computer science focused their attention to the development of theoretic foundations of conceptual models used for designing database and knowledge systems and for creating computer programmes, the information science needs to concentrate upon conceptual models applied to the key objects of its interest. We understand the information science in accordance with the approach of David Bawden and Lyn Robinson as “the discipline of study dealing with registered information with focus onto component parts of the information chain examined via the perspective of the domain analysis“ (Bawden and Robinson, 2017, p. 30). The conceptual models of information science, accordingly, should handle in particular information resources and processes of their collection, processing and utilization.
The text of this article is structured in three parts. The first part formulates the working scope of model and creation of the same, as used in the present text. The characterization of models is proposed by way of a facet structure, based upon the analysis of features, relations and functions of the structural components of the model. The facets freely follow the 5W1H methodology: determining what is being modelled, who is the creator and who the user of the model, what is used for modelling and what the model is utilized for. The second part is devoted to the characteristics of conceptual models. Along with the application of the semiotics perspective, an overall outline of modelling languages is offered, followed by the specification of five functions of models that are of importance for the information science. Then a procedural viewpoint helps to describe three key phases of the creation of a conceptual model. The third part comprises a draft of the typology of the contents and the form of conceptual models that are relevant for the information science. Considering the substantial impact of conceptual modelling in computer science upon the practice of “modern” conceptual modelling in the information science, this part offers also its brief review. The conceptual models in the information science have been split into two groups, the first one representing conceptual reference models and the second group consisting of metadata models covering metadata element sets, metadata schemes and value vocabularies. The characteristic features of various types of conceptual models are complemented by examples of their important representatives. Special attention has been devoted to a specific category of conceptual models in the information science, namely to the knowledge organization systems and their conceptual models.
1 Model and modelling
1.1 Model definition?
The question mark in the title of this part suggests certain doubts whether it can be possible at all to define a model unambiguously. The width and diversification of fields of model utilization and their ubiquity, as has been stated in the introduction already, brought, e. g., Jochen Ludewig (2003, p. 5) even to the allegation that there is no way of arriving at a generally applicable and consistent understanding of the concept of model. Some accordance can be found on a most general level only, namely when a model is declared to be a representation of an object, a phenomenon or a process sharing their substantial properties. The issue which properties are substantial is decided by the purpose of the given model. The aphorism of George Box quoted in the motto of the article is a very apt reflection of this principle: the aim of a model does not consist in being the same as the original, but in serving some concretely specified purpose.
We will understand a model as an artificial creation, i.e. an artefact that is intentionally created by an agent to serve the function of subject for a certain aim. Such creation can be any thought or material construct. A model differs from other artificial creations by its specific purpose, which is the representation of an original in the function of object. The pragmatic aim of such representation can be learning the original, creating or drafting the same, but also developing a pattern of the appearance, structure or behaviour of the original or its optimizing. The specific and differentiating features of the model are, on the one hand side, its relation of correspondence with another object thanks to which this object can be represented and, on the other hand side, its dependence upon the given object. A condition of the existence of a model, namely, is the existence of the represented object – a model is always related to “something” that is called original, irrespective of whether it exists physically (“in reality“), or in our mind only, when we give something a thought, when we conceive3 or plan the same. Such highly abstract definition gets the understanding of model close to the classical semiotic conception of sign, which is according to Charles Sanders Peirce “something that stands for somebody, in a certain viewpoint or in some role, in the place of something else“.4
The diagram in Fig. 1 shows three key entities of model creation – model, original and agent – and their relations. The latter are of two types: relation of direct (concrete) influence and relation of (abstract) correspondence.

Fig. 1 Model, original and agent
There are two key aspects characterizing the relation of direct influence between agent and model. The first is relation (1) – creating the model and utilizing the same by the agent. The relation designated in the diagram by (2) is implemented as an indirect one – the model substitutes the original for the purposes of the agent. A typical substitute relationship is learning the original via its model, e.g. recognizing a region according to its map.
The relationships of direct correlation between the agent and the original can have all sorts of forms; for our purpose the attention will be directed upon the relation within the bounds of which a model is in use. A typical example of such type is the creation or the adaptation of the original according to the model by the agent, see under No (3), e. g. the creation of a document according to a prepared template, or conversion of a bibliographic record into some required format.
The relationship between model and original is described as abstract correspondence relation. A possible impact of the original upon the model, then, is never direct, but it gets implemented by way of the mediation of an agent. Such relation of correspondence is asymmetric, and namely due to two causes. First of all, this relation of correspondence does never originate as a sort of 1:1 equivalence, but as a similarity based relation. This means that the model and the original are never congruent in all their features. A typical example is a model abstracting from all details, which enables its application for a number of objects exactly thanks to this generalization. However, also current are cases integrating various elements into the model that are not comprised in the original (e.g. coordinates in a map), in order that the objectives of the model can be met. Sometimes also a particular type of similarity can be specified, most often via differentiation between isomorphism and analogy. The term isomorphism is used for characterizing the correspondence of form, i.e. the outer outlook, whereas analogy usually denotes a structural (internal, substance oriented) similarity. The second cause of asymmetry resides in that the actual relationship of similarity is exclusively a one-way issue. As indicated by arrows (4) and (5), a model is either similar to the original, or the original is similar to the model, but both can never apply simultaneously. This bipolarity is connected with the problem of descriptive and prescriptive models that will be dealt with in the following part.
1.2 Typology of models based upon facet analysis
Much the same as it is difficult to find a generally accepted model definition, it is not easy to choose one generally acceptable sorting criterion for their typology. The fact that a variety of different viewpoints can be applied in the approach to their typology makes models suitable objects of facet analysis. The facets suggested for the typology of models in this part have been derived from the analysis of properties, relations and functions of the structural components of the model indicated in Fig. 1. The facets specify what is being modelled, who is the creator of the model and who its user, what is being used for modelling and what the model serves for. When drafting them we have loosely draw on the 5W1H method (the acronym has been made from the first characters of questioning pronouns who, what, where, when, why, how). The 5W1H method can be considered as a “naïve“ form of facet analysis. However, its more or less intuitive approach to integral examination has found ample utilization in a number of branches thanks to its clear and easy applicability. Among other authors also Bernhard Thalheim (2011) made use of the same when characterizing conceptual models in computer science by way of facets wherefore, whereof, wherewith, whereto, how, when, for which reason, by whom, to whom, for what, where etc.
Facet derived from the feature of the entity Original/object – WHAT is being modelled
The ubiquity of the models is the cause of the circumstance that the scope of this facet is practically unlimited. The object that is being modelled can be anything, any object of interest of the agent, or even the agent as such or another model (even a model can be subject to modelling – in such case we usually refer to meta-model). “Being original“, accordingly, is not a permanent property of the object, but a role related to a concrete model (in analogy this is valid also for the model).
One of the most general classification criteria in this facet is the viewpoint of time. Conforming to whether certain changes of the original in the course of time are modelled or not, the differentiation is made between static and dynamic models. Static models focus upon reflecting relatively stable structures; an example is the model of bibliographic reference according to the ISO 690 standard or the model of arranging data in the MARC21 format. Dynamic models register processes (an example is the model of business processes represented by way of a flowchart or statechart diagram), but also rules and methods, such as RDA cataloguing rules or methods of bibliometric analysis.
Facets derived from the properties of the entity Agent/subject – WHO is the creator of the model and WHO is its user
It is again true within this facet that both the creator and the real or envisaged user of the model can be anybody – a layman, a professional, an individual, a group or an institution etc. In addition to that the role of creator as well as that of user can be assumed both by a human and a machine.
Facets derived from the properties of the entity Model – WITH WHAT the modelling is done and WHAT the model is used FOR
Also in the case of the facet WITH WHAT the general rule is applicable that the model can be created out of anything, it can be abstract or concrete, it can – but need not – be an object of the same type as the original. Conforming to the degree of abstraction the models can be arranged on a continuous scale from the general (abstract) ones down to concrete models. The differentiation between these two types is guided along the line standing for the share of physical components and their role in the given model. Whereas the physical parts in the concrete models stand for the contents of the model (a gypsum model of a building or a statue, a prototype of a car or of a user interface of an information system can serve as examples), possible physical parts of abstract models serve only for recording the contents of the model, namely as its material carrier.
Another general criterion for sorting the models within the facet WITH WHAT is the degree of standardization and formalization of the applied modelling means. The advantage of standardized tools consists in facilitating communication as well as in sharing the models that have been created. On the other hand, individually developed models enable a higher degree of creativity and often also better precision in capturing the features of the original, though usually for the price of impaired communication.5
As regards their general purpose, the models within the facet WHAT FOR can be classified in groups that will get working names ontological and epistemological. The actual purpose of an ontological model is being a substitute for the original, whereas the primary purpose of an epistemological model is learning the original. An ontological model enables physical handling. An epistemological model contains information of the original, enables understanding, explanation, grasping the original. Jochen Ludewig (2003, p. 8) offers an alternative perspective within which he classifies the models according to their relation to the original as descriptive and prescriptive. A descriptive model describes the original. The object of description can be anything that topically exists, that existed or may come to exist later (in this sense, e.g., also a weather forecast is a descriptive model), but also imaginations or abstract ideas can be part of the game. The objective of a prescriptive model is affecting the original. While a typical case of such influencing is creating an original according to a model, a prescriptive model need not always serve for creating an original – such as a model of social behaviour should ”only” affect the way people behave. In analogy the concept of description and prescription is used in linguistics. František Čermák characterizes the same as “unbiased and true (scientific) description … and authoritarian exclusive prescribing of certain selected forms as appropriate or correct“ (Čermák, 2007, p. 98). Also the practice of terminology differentiates between descriptive work focusing upon the collection of terms from a given field, on the one hand side, and work with a prescriptive purpose aiming at the enforcement of the usage of recommended terms, on the other hand side (Cabré, 1999, p. 32).
Yet another perspective develops a differentiation of models on the background of communication intentions, and namely between internal implicit models, and objective shared explicit ones. These types of models will be dealt with in a more detailed way in part 2, in connection with conceptual models.
Table 1 shows examples of models from the librarian practice, describing them with the help of the suggested facet structure. The models are divided in three numbered groups: group 1 are static models of objects and structures, group 2 are dynamic models of events and processes, and group 3 contains two examples of abstract models of concepts. For being more illustrative, the facets WHAT, WHO and WHAT WITH indicate (in italics) also concrete examples of instances.
Tab. 1 Application examples of the facet analysis for describing models
|
Model |
WHAT |
WHO |
WHAT WITH |
WHAT FOR |
||
| Creator | User | |||||
| 1 | Competition project of a new building of the National library of the Czech Republic6 | static | man | man |
concrete individual |
epistemological prescriptive |
| building | architect (competitor) | jury |
a) analogue (gypsum, paper) b) digital (data) |
|||
| Bibliographical description of a book | static | man | man |
abstract standardized |
ontological descriptive | |
| book | cataloguer | reader | text | |||
| Format MARC21 | static | man | man/machine |
abstract standardized |
ontological prescriptive | |
| Data content | Library of Congress | librarian software | text | |||
| Database scheme of system KOHA | static | man | man |
abstract standardized |
epistemological descriptive | |
| structure of data | data analyst | database administrator | ER diagram | |||
| 2 | Loan recording in the library system |
dynamic |
machine | man /machine | concrete standardized | ontological descriptive |
| loan | library software | reader / librarian / software | data | |||
| Recording methods of bibliographic data in RDA | dynamic | man | man |
abstract individual |
epistemological prescriptive | |
| cataloguing | RDA steering committee (RSC) | cataloguer |
RDA Toolkit7 |
|||
| 3 |
Universal decimal classifier |
static | man | man |
abstract standardized |
ontological descriptive |
|
contents of work |
cataloguer | reader | numeric code | |||
| Information request | static | man | man/machine |
abstract individual |
epistemological descriptive |
|
| information need | user | librarian / software | text | |||
The efforts to achieve unambiguous categorization of models are complicated due to instability and relativity of their components. Not even models changing their purpose in the course of their existence appear to be rare. A usual change resides in that a descriptive model changes to become a prescriptive one. An information request, e.g., is a descriptive model of certain information needs, whereupon it becomes a prescriptive model of a resource request; a requirements specification relating to an information system is created as a descriptive model of user needs, and upon approval it can serve as a prescriptive model for a system that is being developed. The entities of the FRBR model have gone through an analogous transformation, after having turned from the original description of user requirements concerning bibliographic records to become component parts of a prescriptive model – the RDA cataloguing rules.
The relation of similarity between the model and the original, however, can give rise to problems of differentiation between them. Jochen Ludewig (2003, p. 11) draws our attention in this regard to the fact that good models can be that good as to be mistaken for the original. Such situation can occur both in descriptive models and in prescriptive ones. Typical are cases of data models of reality (i.e. models consisting of data) in the computer that are taken for real existence, which need not be only virtual reality. Quite frequent are situations where a mere plan is taken for granted, or where the user mistakenly considers an introduced prototype for a finished artefact.
The relativity of the components is manifested in that the same object can once play the role of model and another time that of original, and namely in different time periods, for different agents or for different purposes. This applies to full extent for the key objects of interest of the information science, such as information, data, metadata and knowledge. Data, namely, can be viewed both as a model representing reality in the information system, and as an original represented, e.g., by a conceptual model of database. That is why it is necessary to clearly differentiate which features, functions and roles of the entities in question we have in mind in the particular case. The decision is fully up to the agent, and it is by far not trivial. The aim of the facet categorisation, as suggested in this part, consist in supporting such decision making by way of a method enabling to determine the differences between the existing types without losing from sight their common aspects.
2 Conceptual model
The most important types of models that are relevant for the information science, and at the same time the most complex ones, are doubtlessly the conceptual models. The first difficulty is encountered with their name already, admitting double interpretation and inspiring the question whether a conceptual model is a model of concepts or a model consisting of concepts8. Available literature focusing upon the theory of conceptual models is seen to confirm the second variant. Generic differences of conceptual models distinguishing them from other types of models create the contents of facet WHAT WITH is being modelled – the tool for modelling is a concept, whereas the contents of the WHAT (is modelled) facet is not being restricted by anything. Thus a conceptual model can be easily defined as a model created from concepts.
2.1 Definition of concept?
The unambiguous determination of concept as the basic structural unit of a conceptual model, however, immediately opens up problems related to its defining, as signalled by another setting of a question mark in the title of this section. The absence of a generally accepted definition of concept has philosophical foundations due to the existence of diversified theories of cognition, not rarely contradicting one another. Accordingly, let us mention right in the introduction that we certainly do not aspire to proposing a clear definition of concept in the present article; on the contrary we try to reflect the complexity of the problems and to characterize the most outstanding perspectives of investigating the concept as relevant from the viewpoint of conceptual modelling in the information science. We will restrict ourselves to a recap of the basic principles and to references covering some selected important sources dealing with the analysis of concept from a perspective applicable in the information science. Contact points shared by most cognition theories can be summarized in the following general statements:
-
A concept is the basic unit of thought. It is considered to be a cognitive model of existing knowledge, enabling its utilization for learning new objects or events.
-
The properties of concept are created by the dialectic unity of intension (contents, most often determined by a plurality of characteristics or definitions) and extension (scope, the plurality of things comprised within the concept).
-
The process of creating a concept or conceptualisation is a unit of the (passive) reflexion of reality and (active) construct of the meaning.
-
The process of conceptualisation is based upon abstraction – in generalizing and reducing the potentially infinite set of characteristics of the reality, it can comprise more objects, thus approaching the process of categorisation. An extension of category is a set of things considered as equivalent from a certain viewpoint or for the given purpose.
A detailed review of research in this field down to the present day from the sight of cognitive linguistics was offered by George Lakoff (2006) who formulated the theory of idealized cognitive models. Lakoff puts the “traditional“ Aristotelian theory of creating concepts, based upon the common features of comprised objects, into counter-position of the results of empiric investigations of human thought in the course of the 20th century. He highlights in particular the prototype theory of Eleanor Rosch and the principle of the so-called family resemblances, as formulated by Ludwig Wittgenstein. A suitable complement to the text of Lakoff, focusing upon human cognition, is the interdisciplinary study of Joseph Goguen (2005), directed to the methods of machine based creation of concepts upon mathematical foundations (one of the mentioned examples being formal concept analysis), as well as their applications in computer science, artificial intelligence and knowledge representation. The machine methods of concept creation abstract from the ”human” side of the process as the cause of ambiguity and instability of meaning and of unclear relations between the concept and its articulation. “The concept of concept“ seen in a detailed historical retrospective and with regard to the context of the information science has been analysed by Alberto Marradi (2012). The investigation of concepts within the theory of cognition involves also the problems of representing their contents. This theme was handled by Elaine Svenonius (2004) in her study devoted to epistemological foundations of knowledge representation. Contrary to current understanding of knowledge representation as a discipline of artificial intelligence, she applies a broader vista that is not limited to the issue of mediating knowledge to the machines. She offers a review of three theories of meaning that were dominant in the philosophy of the 20th century: operationalism, referential or picture theory and the contextual/instrumental theory of meaning. Operationalism, sorting out of the theory of logical positivism, defines the concepts procedurally, by way of generalizing empirical data. As to the referential theory, we will handle it with more detail in part 2.2. The instrumental theory of meaning determines the sense of concepts within their utilization in a particular context. Svenonius observes these theories from the viewpoint of their application in the course of processing and searching for information. She uses criteria relevant for the information science for comparing them: validity of knowledge representing, support of collocation functions, discrimination and navigation, suitability for automation and possibilities of semantic interoperability.
2.2 Conceptual model in the semiotic triangle
The fact that the basic building unit of conceptual models is a concept requiring to be expressed by some sort of sign, is an invitation to apply the knowledge apparatus of semiotics. For the purpose of this text we will use the currently accepted referential triadic concept of sign, as represented traditionally by the semiotic triangle. Our working interpretation of the semiotic triangle in Fig. 2 makes use of the terms thing, concept and designation for the three basic aspects of sign. The relation between concept and thing as its extension is designated as conceptualisation, i.e. conceptual processing of a thought idea about the meaning of the reality. The relation between concept and its designation is called expression. The relation of reference directed from the designation towards the thing is understood as an indirect one that is mediated by conceptual representation, and that is why it is shown by a dotted line. In fact, however, the path of reference from the sign to reality leads in the direction designation - concept - thing.
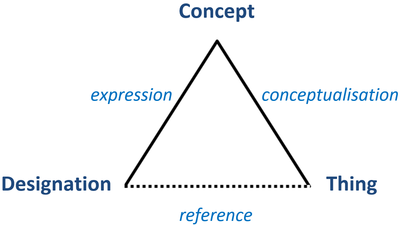
Fig. 2 Concept and its designation in the semiotic triangle
The perspective of model creation enables a statement to be made that the concept in the semiotic triangle represents/models the thing, whereas the designation/name represents/models the concept. The apex of the semiotic triangle indicated as thing, accordingly, comprises the contents of the facet WHAT is being modelled. It expresses that anything can become the object/original of a conceptual model, i.e. the conceptual model can (but need not) model also concepts and their designations. Thus, to offer an example, terminological vocabularies or thesauri can be understood as conceptual models of language expressions – the international standard ISO 704 devoted to principles and methods of terminological work directly mentions the analysing and “modelling concept systems on the basis of identified concepts and concept
relations“ (ISO 704:2009, p. v).
2.3 Languages for expressing conceptual models
As has been stated, a conceptual model is a thing created by concepts. A concept, however, is not communicable (it is implicit, tacit); for any communication or handling it shall be expressed by some language. Accordingly, the format of a conceptual model is a modelling language.
A systemic approach enables to define the language as a unity of structure (i.e. elements of the language and their correlations) and function. For our purposes, however, we will restrict our scope to the referential function and the following structural elements of the language: vocabulary, rules, paradigmatic and syntagmatic relations. The languages applied for expressing conceptual models represent, as concerns the complexity of their structures and functions, a broad spectrum whose beginnings can be seen as far as at the level of character formats (such as Unicode) and continuation in the form of languages characterized by syntax of variegated granularity and all sorts of techniques or formats (such as HTML, XML, RDF, JPEG, PNG, PostScript, SVG). We will focus upon semantic languages enabling the expression of concept contents and their correlations in conceptual models. They exist as a considerably extensive group at the present day, offering diversified classification criteria, such as according to granularity, i.e. the “size“ of the covered contents, according to the modelled entities, according to the degree of formalization or the form in which the contents of the model is expressed.
Assuming the viewpoint of granularity, let us mention at least the classification of languages in groups intended for modelling the contents on the level of the whole document, or even on the level of a collection of documents, called macro-indexing (e.g. Universal Decimal Classification), and languages enabling the so-called micro-indexing on the level of units of contents, based for instance upon the creation of statements creating the contents of knowledge bases, or even single items of subject indices of books.
According to the entities being modelled (contents of the WHAT facet) it is possible to differentiate between languages specialized to the handling of software applications (such as ER, UML, SQL Schema, BPMN), languages expressing the structures of electronic documents (such as DTD, XML Schema), languages for the semantic web, web sources and services (such as RDFS, OWL, SKOS), and possibly for modelling objects in the applications of artificial intelligence (such as KIF, Topic maps).
The viewpoint of formalization degree enables the statement that the languages expressing the semantics of conceptual models form a continuous scale from the not formalized to fully formalized ones. However, this continuous scale allows to discover certain thought boundaries separating the following types of languages: fully informal natural language, partially formalized natural language (such as language with a controlled vocabulary or the so-called special languages comprising professional terminology), formalized artificial language (e.g. ER, BPMN, SQL Schema, XML Schema, RDFS, OWL, UML), and finally the rigorously formal language of logic (the most often frequented are the languages of propositional, predicate and descriptive logic).
The form of expressing the contents of a conceptual model enables the differentiation between textual languages (verbal, numerical) and pictorial ones applying static pictures or video as media of expression. A free text written down in some of the natural languages is a fully informal method of textual expression. The tools serving to the formal textual expression of the hierarchical structure of electronic documents are the languages DTD (Document type definition) and XML Schema. The textual modelling of vocabularies in the environment of the semantic web is achieved with the help of languages RDFS, SKOS and OWL. Most pictorial languages are founded upon semantic networks, i.e. their semantic relations can be represented (visualized) in form of a graph. The existential graphs of Charles Sanders Peirce are held to be the first utilization of semantic networks for the representation of concepts. A specific applications of a semantic network are, e.g., the models expressed by way of diagrams in the languages ER or UML that appear to be the most important formal way for the representation of conceptual models in the graphic form. ER is the language of entity-relationship model/diagrams, which gave them the name. Sometimes also the acronym E-R or ERA (standing for entity-relationship-attribute) can be found. Beginning from the 70ies of the 20th century it is used in particular for designing the models of relational databases; a classical variant is the original proposal of Peter Chen (1976). UML (Unified Modeling Language) has been the standard for the representation of object oriented models from the 90ies of the 20th century (OMG, 1997). Having been originally proposed for the modelling of software applications, it is found to have gradually spread also into other fields. An interesting example in this respect is the standard ISO 24156-1 specifying the UML application profile for the utilization of its graphical notation in the terminology work (ISO 24156-1:2014).
Much the same as language has a retrograde impact upon thought, also the selection of language for the expression of a conceptual model can affect its sense. Thus the choice of the language UML or RDF, as a rule, leads to the application of an object oriented paradigm in the given model, whereas the ER language of the models tends to the orientation of being implemented in relational databases.
2.4 Functions of conceptual model
The functions of a conceptual model can be specified by means of the above components of the semiotic triangle, the thing and the designation. However, instead of a single concept we will consider a set thereof, i.e. a set of concepts connected by their correlations, creating together the conceptual model. Fig. 3 shows five functions, being a selection of types considered by ourselves as relevant from the perspective of information science. The functions labelled by characters a – e are indicated by arrows standing for the processing course that are directed from the source entity towards the target one which is its transformation. Each function is described in a structural way – after characterizing the given course of processing particular examples of the source entities and the target ones is given.

Fig. 3 The functions of a conceptual model
(a) Creation of a conceptual model of reality
Characteristics of the process: conceptualisation, i.e. creation of a conceptual model of reality.
Source entity of the process: a thing in the function of original; the scope of this entity is not limited; anything observable or thinkable can be modelled.
Result (output) of the process: a descriptive conceptual model expressing the contents, the sense, the meaning of reality. Examples: domain ontology, knowledge organization system, database model.
(b) Creating a conceptual model expressing the contents of a sign
Characteristics of the process: interpretation of the meaning of the designation as a specific case of conceptualisation. The foundation of conceptualisation in this case is the content analysis of the information sources. Its specificity resides in that no analysis of the thing is carried out, but the meaning of the given text/sign gets interpreted. Texts of the information science utilize a special term for this process, and namely indexing; standard ISO 5963 defines indexing as “the act of describing or identifying a document in terms of its subject content“ (ČSN ISO 5963, 1995, p. 5).
Source entity of the process: designation in function of the original; possible types of languages for creating the designation have been characterized in part 2.3.
Result (output) of the process: descriptive conceptual model as the result of the analysis of content of the designation (text, document, information source), generally known as aboutness (Kučerová, 2014). Examples: metadata, search pattern of the document, reduced text (e.g. abstract).
(c) Creation of artefact according to a conceptual model
Characteristics of the process: creating or modifying an original according to a model, such as cataloguing (creation of a catalogue entry) under the RDA rules or creation of a database according to a conceptual scheme.
Source entity of the process: prescriptive conceptual model, such as RDA cataloguing rules, conceptual database schema.
Result (output) of the process: thing in function of original – artefact created according to a model. Examples: catalogue entry, database table.
(d) Creation of signs as implementation of a conceptual model
Characteristics of the process: expressing the contents of a model mediated by some language, eventually its formalization under agreed rules.
Source entity of the process: conceptual model in function of original.
Result (output) of the process: designation – conceptual model expressed in the language system agreed upon. The existence of a plurality of modelling languages (see part 2.3) gives rise to the option of implementing one model in various ways in a number of languages. Examples: database schema expressed by ER diagram or by the class diagram in UML, domain ontology expressed by languages HTML, RDF or OWL, knowledge organization system (e.g. thesaurus) expressed graphically in form of semantic network or verbally in the SKOS language.
(e) Creation of model according to model
This rather anecdotic name designates a process in whose course a new model gets created with the utilization of an existing one.
Characteristics of the process: adaptation (reusing, modification, transformation) of the original model and the creation of a new one.
Source entity of the process: conceptual model, such as a Dublin Core metadata element set.
Result (output) of the process: conceptual model derived from an already existing one. Examples: application profile created under the Guidelines for Dublin Core Application Profiles (Coyle and Baker, 2009), UML application profile, conceptual model or domain ontology created with the utilization of the foundational ontology or design patterns.
2.5 Processes of creating conceptual models
The understanding of the specificity of conceptual models can be suitably facilitated by focusing upon the procedural viewpoint itself. The overall procedure of conceptual modelling is shown in Fig. 4. It consists of three phases following upon one another: creation of a subjective model and the creation of an objective one that is further classified in sub-processes of the expression of a subjective model and the physical implementation of the model. Models having arisen in the first phase are denoted as number 1, the model created in the second phase is found in 2.1 and the model created in the third phase under 2.2.
An illustrative differentiation of the phases can be achieved, if we apply the thesis of objective knowledge and the metaphor of three worlds, as formulated by Karl Raimund Popper in his theory of knowledge. Their suitability for application in the information science can be seen in that they handle not only the problems of cognition in the human mind, but also the detailed problems of knowledge registered in external memories. Popper coins a thesis about two types of knowledge – subjective and objective ones. Subjective knowledge, in his idea, is the one that is owned by some subject; it is represented by the state of mind or conscience or by being disposed to act or to react. On the other hand, he denotes objective knowledge as “knowledge in the objective sense, consisting of the logical contents of our theories, hypotheses, guessing“ (Popper, 1979, p. 73). “Knowledge in this objective meaning is totally independent on what anybody allegedly knows, it also does not depend upon anybody´s conviction. Knowledge in the objective sense is knowledge without the knower (it is knowledge without a knowing subject)“ (Popper, 1979, p. 109). Popper´s theory of three relatively autonomous worlds is based upon the philosophy of Bernard Bolzano and Gottlob Frege. It divides the objective reality in world 1 – the physical world of mass and energy, world 2 – the world of human conscience (states of awareness, subjective knowledge) and world 3, which is the world of speech – the abstract world of the contents of conscience and of the artefacts of human spirit (objective knowledge). There are boundaries between worlds 1, 2 and 3, and these borders are at the same time also places of interaction. Direct interaction, however, between world 1 and world 3 is not possible according to Popper; it can be materialized only by the mediation of world 2. World 3 is a creation of Man, i.e. an artefact that is a product of world 2.
Fig. 4 shows that the models created in the first phase fall into Popper´s world 2, whereas the models created in the following two phases pertain to Popper´s world 3. The materialized model created in phase 2.2, naturally, already contains some elements of the physical world 1.

Fig. 4 Phases of model creation
Phase 1 – creation of subjective model
A subjective model originates in the course of thinking. It is denoted, among others, as implicit, tacit, mental or cognitive model or representation, or conceptual structure. According to George Lakoff “cognitive models help to structure thinking and are used for the formation of categories and thought“ (Lakoff, 2006, p. 26). Subjective models are investigated by psychology, the cognitive science and the artificial intelligence with the aim of learning and explaining the substance of human thought. The research of the principles of human thinking has resulted in profiling a plurality of alternative ideas, of which quite a number consider modelling to be a basic process, or even method of human thinking. A detailed review of these problems from the viewpoint of cognitive psychology has been offered by Miluše Sedláková (2004).
As regards the standpoint of purpose, it seems to be appropriate to differentiate between two types of subjective models. The first type is the implicit model created by an individual for his/her own need, as a rule designated as mental model. Let us give the second type currently lacking any specific designation, the working name being subjective conceptual model. Actually, it is also an implicit model created by an individual, but this time with the intention to express the model and to use it for communication. Mental models are created subconsciously, intuitively, and are held for a component part of long-term memory. They are created by individuals for themselves and utilized for understanding the world or for problem solving. No possible externalization of mental models is seen to be within the intentions of their authors, but of researchers who apply various methods for their determination.
As to computer science, the mental models study in particular the user on the one hand and the information system or application on the other hand, and namely in the context of their interactions. The most frequented object of interest is the mental model of functioning of the system that is created by its end user. The usual hypothesis reads that as long as the information system corresponds with the mental model of the user, it will be readily accepted and the interaction user – information system will be successful.
The information science, too, is interested in mental models when investigating the interactions between the user and the information system, especially as integrated in the research of user behaviour. A review of numerous research projects relating to this topics is given, e.g., by David Bawden and Lyn Robinson (2017, p. 251–277). An interesting example is the research work that was part of the historically first user testing of the FRBR model, whose results were published by Pisanski and Žumer in 2010 (2010a, 2010b). Its objective consisted in elicitation (i.e. determination and explicit expression) of internal subjective mental models of the bibliographic universe, followed by ascertaining whether the mental models of the users of bibliographic information are compatible with the FRBR model. The course of research involved various techniques of card sorting, conceptual mapping (i.e. knowledge representation by way of diagram) and comparison with the results of steered interviews.
The second type of model, for which we use the working designation subjective conceptual model, gets deliberately created in the mind of the individual with the intent of transforming the same in an objective and explicit model that should be shared with somebody. A subjective conceptual model is being created in the human mind as an indispensable pre-stage for being expressed in the form of an objective model. Its substance is conceptualisation and categorisation, i.e. the creation of concepts and conceptual systems. The actual purpose of this model type, accordingly, is the creation of an objective model; it is developed for the purpose of externalisation and sharing (i.e. communication).
Phase 2 – creation of an objective model
As shown in Fig. 4, the creation of an objective model consists of two partial phases: explicit expression of a subjective model and the physical implementation of the same.
Phase 2.1 – expression of a subjective model
This is an abstract model. It is expressed by some sort of language, i.e. it is represented. It enables the communication of the semantics of the subjective model in the sense of sharing and, possibly, transferring in space, but not preserving the model in time or physical handling the same, either9. Such activities are possible only after the following phase that consists in the physical implementation of the model.
One of the methods of externalizing mental models is the description of behavioural patterns where the internal mental models manifest themselves. The standard method applied for externalizing subjective conceptual models uses semantic networks (languages serving for their expression have been characterized in part 2.3).
Phase 2.2 – materialization of the model
The result of this phase is a concrete model, typically created by capturing the semantics of the model expressed in some language on a material carrier. The choice is open; the materialization of a conceptual model can be achieved both by an analogue carrier and a digital one (such as paper, microfilm, flash disk)10. In addition to communication in time a concrete model enables direct handling, such as experimenting with the model or its physical organization by location.
3 Review of conceptual models relevant for the information science
We will use our own typology based upon the contents of the facet WHAT is modelled to prepare a review of conceptual models that are relevant for the information science. The following overview in Table 2 is introduced by universal semantic models in form of foundational ontologies. The next are semantic models limited to the specific field of interest – domain ontologies and conceptual reference models. Another group are metadata models. These are divided into the group of static models and dynamic ones, the static ones are further subdivided to metadata element sets and metadata schemes and to value vocabularies. The review is terminated by models of entities in an information system or in a software application, i.e. conceptual schemes and data models. The already mentioned impact of conceptual modelling in computer science upon the theory, and especially upon the practice of modelling in the fields investigated by the information science, has been demonstrated by incorporating ”the own” conceptual models of the information science, as indicated in the highlighted central part of the chart, in the context of the models of computer science. This context operates on the most general level of foundational ontology, but also on the concrete level where conceptual schemes and data models are created.
Tab. 2 Typology of conceptual models relevant for the information science
|
ontologies |
foundational ontologies |
|
|
domain ontologies / conceptual reference models |
||
|
metadata models |
static |
metadata element sets and metadata schemes |
|
value vocabularies |
||
|
dynamic |
rules, methods |
|
|
conceptual schemes |
||
|
data models |
||
3.1 Conceptual models in computer science and their terminology
Taking into consideration that the theory of conceptual modelling, as developed in the field of computer science, represents the key source for the information science, we feel that it is appropriate to offer its overall characteristics. However, due to the rich existing bibliography focusing upon this topic, we will restrict ourselves to a brief summary covering in particular the current terminology. Let us refer anybody interested in a historical review of conceptual modelling, e.g., to comprehensive studies worked out by Janis A. Bubenko (2007) or Nick Roussopoulos and Dimitris Karagiannis (2009). Let us name, among the outstanding authors and theorists of conceptual models in computer science, the author of the concept of entity-relational modelling of data Peter Chen, the representative of the Scandinavian school of conceptual modelling Arne Sølvberg, the author of the important database model Telos John Mylopoulos and the German theorist in this field Bernhard Thalheim.
Of course quite diversified approach can be found in the great amount of published works. Anyway, the understanding of conceptual models as artefacts representing knowledge of entities relevant for the information system intended for people is seen to prevail. Thus the conceptual modelling differs from the knowledge representation intended for machines. The problems solved by the theory of conceptual models in computer science can be summarized in two basic areas. The first one searches for an answer to the question what is being modelled – where these are objects in reality or objects in an information system/application. The second circle of problems covers the solution of the automatic transformation of a conceptual model to a software artefact or an application (the so-called forward engineering) and the contrary (the so-called reverse engineering).11 Tuned-in with the engineering character of their discipline, the computer science experts concentrate in particular upon the prescriptive models. The effort to create theoretical foundations for the conceptual models in computer science has led some authors down to the philosophical roots of modelling. E.g. Yair Wand and Ron Weber (1990, p. 63) selected the ontology of philosopher Mario Bunge as the basis of their theory of information systems.
The present day stage of development of information technologies has enriched the problems of conceptual modelling by the topics of ontologies that are seen to quickly penetrate from the original application field in the systems of artificial intelligence into all sorts of domains, including librarianship and information science. Ontologies represent a highly actual and important topics whose detailed analysis, however, would require a separate study. We will restrict ourselves in the present text to briefly characterising ontology as a specific type of conceptual model aiming at communication, repeated usage and organization of knowledge, description of reality for computer processing and automatic deriving of knowledge. Its contents are classes whose meaning is defined by axioms. The choice of classes, their features and the way of structuring the ontology is based upon implicitly or explicitly determined ontological commitments.
From the numerous classification options of ontologies, the one based on delimitation of the set of represented entities and thus following the contents of the facet WHAT is being modelled, offers relevant typology for our purposes. On the basis of this criterion the ontologies can be divided into the generic ones (also universal) and the domain ones. The generic ontologies have a general focus, are domain independent and unlimited as to scope. A specific type of generic ontologies are the foundational ontologies, whose purpose consists in serving as a starting point for the creation of new domain ontologies. They comprise entities for reuse, usually basic categories on the highest level of universality, and sometimes also design patterns. The domain ontologies are restricted to a concrete region that is delimited thematically, but it can be defined also according to the problems – thus it is possible to differentiate between ontologies focusing upon descriptive knowledge on the one hand and procedural ones on the other hand. As will be shown in part 3.2, domain ontologies can be encountered also in the field of memory and fund institutions at the present day.
The terminological base of conceptual modelling in informatics, having been registered and standardised on the level of Technical Report ISO/TR 9007 as early as 1987, is further developed by the international consortium OMG (Object Management Group) that was founded in 1989. OMG associates roughly 300 technological, researching and consultation organisations and devotes attention to the standardisation of object oriented tools and methodologies.
The standard ISO/TR 9007 (ISO/TR 9007:1987) defines two levels of modelling reality in information systems: the level of contents (i.e. intension) is depicted by the conceptual scheme, whereas the scope (i.e. extension) is depicted by the database. The conceptual scheme describes the semantics of data, whereas the database is understood as the data model of reality. In addition to these models the standard defines further two types – the so-called external scheme (system as observed by the user, i.e. a model of the outer interface between the user and the information system) and the internal scheme describing the technology of the physical saving of data in the system and their handling (i.e. a model of the interface between the information system and the used data saving means).
The MDA – Model driven architecture (OMG, 2014) specification has been the current implementation of the conceptual modelling principle since 2001. Its aim consists in standardising model types that are common for most systems and the automatized transformation of various levels of models in both senses (i.e. both forward and reverse engineering). The concept of architecture of the information systems and software applications according to MDA covers three types of gradually concretized models representing the levels of their description.
The most general level defines conceptual models that do not depend upon computer processing (CIM – Computation Independent Model) catching the description of the application field of the system, such as a model of business processes. Since the nucleus of this system, as a rule, is a vocabulary delimiting the meaning of concepts in the application domain and the rules determined for the course of business processes, also further OMG standard can be used for the creation of this model – Semantics of Business Vocabulary and Business Rules – SBVR (OMG, 2017). SBVR can be held for a highly generalized metalanguage enabling the expression of a business model in a standardized way. One of the application domains is the transformation into an information system model. The contribution of SBVR resides in its focus both upon the description of a static structure by way of a vocabulary, and on the description of a dynamic structure of business processes mediated by a formalized model of their rules. Thus it represents a certain parallel to the current efforts to formalize the RDA cataloguing rules and a possible inspiration for their further development.
Further two models differ as concerns their dependence upon the platform, the latter in MDA being considered as the set of resources upon which the given computer system has been created and that is used for the implementation or the support of the system. A conceptual model that does not depend upon the platform (PIM – Platform Independent Model) stands for a conceptual model of reality represented by the information system on the semantic level, without any data about their implementation in a specific computing environment. A model for a concrete platform (PSM – Platform Specific Model), on the other hand, serves for modelling objects in a particular information system or application.
Three types of models defined in the MDA specification roughly comply with the following types of conceptual models whose working description can be found in Tab. 2: the CIM model has the character of domain ontology, the PIM model corresponds with the conceptual scheme according to ISO/TR 9007 and the PSM model, corresponding with the internal scheme of the information system according to ISO/TR 9007, represents a data model.
As concerns the conceptual models in computer science, it is appropriate to point to some specifics of the used terminology. It can be stated, with a certain simplification, that the current English term for the semantic model of reality is conceptual model/scheme, whereas models of data in an information system are designated as data model/database scheme. The Czech equivalents for data model (i.e. datový model) and database scheme (i.e. databázové schéma) have become current without any problems. However, a certain double-track can be found as regards the equivalents for conceptual model and conceptual scheme. The Czech translation of the ISO/TR 9007 standard, published in 1995, uses the term “pojmové schéma” (ČSN ISO TR 9007, 1995). In the follow-up years, anyway, the Czech community of computer science has adopted the term “konceptuální model/schéma”, obviously under the influence of English sources. These anglicisms begin penetrating from the original field, namely the modelling of database and information systems, also into the fields of conceptual modelling in the information science. Anyway, as will be shown in the next part, the conceptual models in the information science have their own specific features, differing quite substantially from the conceptual models and schemes of informatics. That is why we consider as appropriate to limit the usage of the Czech terms “konceptuální model/schéma” to the exactly delimited domain of their origin, and to use the designation “pojmové modely” for conceptual models within the scope of interest of the Czech community of information science.
3.2 Conceptual models of the information science
The memory and fund institutions, naturally, have at their disposal operational and administrative systems whose conceptual models should be based upon theoretical foundations formulated by computer science. However, much the same as the computer science theory of conceptual models is adapted to the specificity of modelling in computer science, it is necessary to direct the theory of conceptual models in the information science upon the specific objects of its investigation, namely the information sources and the processes of the communication chain, wherein the process of content analysis and the indexing of the information sources play important roles. The first step in this direction was the FRBR model. Originally it was described as a model intended for the designers of library information systems. At the present day IFLA LRM, its consolidated version, has been declared to be the conceptual model of the bibliographic universe, representing an outstanding impulse for the development of theoretical thought in the information science for the 21st century.
Our focus in the following three parts will be the characteristics of three types of conceptual models in the information science: conceptual reference models, metadata models and knowledge organization systems and their conceptual models.
3.2.1 Conceptual reference models
The attribution “reference“ is used for models on the highest level of abstraction that focus upon explicit depicting of the semantics of the respective domain. It can be stated that the models of this type fall into the category of domain ontologies, or there create a special group thereof. Without being intended for direct implementation in the information systems, they represent a conceptual foundation for all further specific models and normative documents within their domains. This feature gets them close also to the category of foundational ontologies. A typical example of a reference model is the model of the open archival information system, as available in the Czech translation of 2014 (ČSN ISO 14721, 2014).
The most important conceptual reference models catching the entities within the field of interest of the information science are the conceptual model of bibliographic information IFLA LRM (Library reference model)12 and the conceptual model of information about the cultural heritage CIDOC CRM (CIDOC Conceptual reference model). Thanks to their high extent of formalization and involving the general concepts for expressing the characteristics of time and space, as well as abstract concepts, both models can be declared to possess also some features of foundational ontology.
The conceptual reference model IFLA LRM (IFLA, 2017), whose domain is delimited as the bibliographic universe, is an important contribution to the creation of the domain ontology for the field of libraries. The specification of the model was adopted as the IFLA standard in 2017, and namely as one that fully replaces the conceptual FRBR models (Functional requirements for bibliographic records), FRAD (Functional requirements for authority data) and FRSAD (Functional requirements for subject authority data).
The purpose of the IFLA LRM model is to provide a framework for the analysis of the logical structure of information relating to library sources from the viewpoint of their users. The same as the models of the FRBR family, the IFLA LRM models information, traditionally designated as bibliographic and authority data, it does not focus upon administrative and operational data. The language for expressing the IFLA LRM conceptual model is the language of entity-relational models as has been used in the FRBR model already. However, this time the language has been applied in the expanded EER version (enhanced entity-relationship model/diagram) enabling also to model hierarchical relations of generalization and specialization, as well with inheritance of attributes and relations. This aspect draws the chosen methodology closer to the methods founded upon object oriented approach.
The framework of this model comprises 11 entities connected by way of hierarchical and associative relations. The entity res (from Latin thing), integrating all entities of the bibliographic universe, is located on the highest level of the hierarchy. The subclasses of the entity res are work, expression, manifestation, item, agent with its subclasses person and collective agent, nomen (from the Latin name), place and time-span.
The conceptual reference model CIDOC CRM was created by the International Committee for Documentation of the International Council of Museums ICOM as the domain ontology for the exchange of documentation about the cultural heritage (ICOM/CIDOC Special Interest Group, 2003). Contrary to the IFLA LRM model CIDOC CRM is from its first version of 1996 based upon the object oriented approach. The present day version 6.2.3 comprises 82 classes and 262 predicates. The top of the hierarchy locates the class called CRM entity, consisting of five upper classes: temporal entity, persistent item, time-span, place and dimension.
The efforts to achieve a semantic interoperability of IFLA LRM and CIDOC CRM reference models are manifested not only on the level of expert consultations and cooperation of professionals from both communities, but also in the form of a draft of a harmonized model integrating entities from both models. The model designated as FRBRoo (IFLA, 2015) has been available from 2009 in gradually developing versions for the whole family of the FRBR models. Following the adoption of the IFLA LRM model the LRMoo Working Group was established in 2017 that launched the revision of FRBRoo and begins preparing a project of an object oriented model LRMoo (Riva and Žumer, 2018).
3.2.2 Metadata models
Contrary to the conceptual reference models, the direct utilization of the contents of the conceptual models of metadata is expected in the procedures of information source processing. Actually, their name suggests that the subject of modelling is limited to a specific set of objects, namely metadata.
The usage of the term metadata began with the onset of digital sources, whereas the name secondary document used to be current in the period of analogue documents for such document type. Also the term metadata, in spite of its name suggesting the interpretation in the sense “data about data“, or possibly “information of information“, denotes a specific type of information source. The specificity of metadata does not reside in their form, but in the contents that is always related to some information source. A typical purpose of metadata is a replacement (surrogate) of a source. Metadata often serve as a reference for a source, i.e. certain access point, however, they can include information complementing the contents of a source. In all cases of their application metadata can be understood as representatives, i.e. models of information sources.
Metadata can be the physical component part of a source (such as imprint, ex libris, metadata in a HTML document), or they can refer to the same (such as a bibliographic reference, catalogue entry, URL, descriptor, UDC classmark). Metadata can be contents related, identifying, administrative and other, being differentiated according to the attribute or function of the source they are related to. The most important ones from the user perspective are metadata enabling the access to sources. Conforming to the chosen principle of source organization, the access metadata contain either an address (location) or a designation of the source. The same as in the world of physical objects, accordingly, the model of physical access to the organized sources is a map of their location created by metadata in form of an index, catalogue or register. In analogy, a certain “map” of their designation, or a model of the network of their correlations, are the knowledge organization systems.
The application practice of libraries and memory institutions comprises both the static and the dynamic metadata models. There are also cases of so-called “hybrid“ models; e.g. the RDA cataloguing rules contain both the list of structural descriptive elements and the prescribed procedures for their determination. Also the text of the ISO 25964 standard, which will be mentioned in a detailed way in part 3.2.3, catches both static and dynamic aspects of the standardization of thesauri and further systems of knowledge organization.
The above option to view metadata as a model reminds us of the fact that metadata can be related with the already noted problem of differentiating between the original and the model. Again the question arises whether (or rather when) metadata are model or original, and again it will be confirmed that a multi-criterial facet analysis will be indispensable for answering the same. Fig. 5 shows both possible variants by way of poly-hierarchic relations in the UML diagram: metadata as a conceptual model of the information resource, on the one hand, and metadata as an original whose structure is modelled by the conceptual model of metadata, on the other hand.

Fig. 5 Metadata as model and as original
Static metadata models
Concerning their semantic structure, metadata can be held for instances of properties whose basic structural elements are created by a pair of attribute-value. Two basic types of structural metadata models are then derived from the existence of the given pair – models of attributes and models of their values. Their names have already become generally adopted as metadata element set or metadata schema and value vocabulary. They are used, among others, by Marcia Lei Zeng and Jian Quin in their monograph Metadata (Zeng and Quin, 2016). Also the authors of the technical report of the American National information standard organization NISO TR-06-2017, focusing upon problems of vocabulary management, sort metadata models that are relevant for the field of bibliographic information in these two basic types (NISO TR-06-2017, 2017, p. 2). The same terminology is applied also by the RDA13 cataloguing rules.
Metadata element sets and metadata schemes
Metadata element sets and metadata schemes represent conceptual models of metadata attributes, including possible depicting of their relations. An important repository for metadata element sets in the format of linked open data is the Open metadata registry that is operated by a non-profit society Metadata Management Associates.14 Among others it contains a list of data elements of Dublin Core, ISBD, MARC21, RDA and UNIMARC.
Value vocabularies
The name suggests that these types of conceptual models consist of arranged word lists, most often terms, designating concepts in the given field of interest. Registers or lists of terms and vocabulary encoding schemes under the RDA rules can serve as example, such as a list of values for the field type of contents15, whose present form contains 23 names of possible values of field 336 in MARC21 format (e.g. cartographic image, computer program etc.).
One of the most important types of vocabularies of metadata values are sets of professional terminology registering the conceptual foundation of the respective discipline in terminological vocabularies and databases. The terminological base of the information science and the field of information technologies are covered by the standards ISO 5127 Information and documentation – Foundation and vocabulary16 and ISO/IEC 2382 Information technology – Vocabulary17. The Czech terminology in the scope of over 3 000 terms can be found in the Czech terminology database of library and information science (TDKIV).18 An outstanding terminological source is the multilingual vocabulary of terms and concepts of the cataloguing domain MulDiCat that serves as source for authoritative translations of IFLA standards and documents. The topical version of 2012 contains 41 terms in 26 languages including Czech.19
Dynamic metadata models – rules and methods
The texts of standards and rules represent procedural metadata models regulating the working processes of their creation and administration. As concerns the creation of descriptive metadata, the governing role is played by the International cataloguing principles, ICP (IFLA, 2016). The general cataloguing principles serve as foundation for the rules; the most amply used cataloguing rules for describing and ensuring access to sources in the memory institutions at the present day are seen to be RDA (Resource description and access). As concerns the methodology of the indexing process, the first international standard was adopted in 1985, ISO 5963 Methods for examining documents, determining their subjects, and selecting indexing terms (ČSN ISO 5963, 1995).
3.2.3 Knowledge organization systems and their conceptual models
Knowledge organization systems
The knowledge organization systems are specific representatives of conceptual metadata models. An idea of the number of systems of knowledge organization in use and of their types can be obviously provided by the most representative register of the present day, namely BARTOC (Basel Register of Thesauri, Ontologies & Classifications), integrating information of 2 857 systems as per 20. 9. 2018.20 An example of a knowledge organization system trying to achieve full conceptual coverage of the information science domain is the faceted thesaurus ASIST (ASIS&T thesaurus of information science, technology, and librarianship) whose third edition of 2005 comprises 1 970 terms sorted in 18 facets with 10 sub-facets. The primary purpose of the thesaurus is indexing and searching for sources in professional databases and digital libraries (Redmond-Neal and Hlava, 2005).
Whereas a problem arises in the case of metadata, namely whether they should be understood as model or as original, there is an ambiguity in the case of the knowledge organization systems in the sense whether they should be understood as a metadata scheme or as a value vocabulary. A separate study has been devoted to this intriguing problem (Bratková and Kučerová, 2014) that was directed upon defining the knowledge organization systems and their typology. Let us introduce at least a brief recap of their conclusions in this place.
We understand a knowledge organization system as a device functioning for the support of the processes of organizing knowledge and access to the same. It consists of a conceptual model of metadata structure (i.e. elements and their interrelations) that are used for the description of organized resources and for their retrieval.
As viewed from the perspective of metadata scheme, a knowledge organization system can be understood as a structural model of an organized set of information sources. The basic structural elements of the knowledge organization system in this approach are concepts and their relations.
However, from the perspective of a metadata value vocabulary a knowledge organization system can be observed as a dictionary representing a formal expression of concepts. Such dictionary is used both for the expression of the semantics and the syntax of the organized whole, and possibly also of the rules that are decisive for the usage of the structure. The term, accordingly, is the basic structural element of the knowledge organization system in this approach.
Conceptual models of knowledge organization systems
This group is an illustrative example of meta-models standing for “model of model” or “structure of structure” of metadata, and possibly “metadata scheme of metadata scheme”. The conceptual models of the knowledge organization systems whose examples are the thesaurus model in standard ISO 25964 and the SKOS model mentioned below, enable theoretical research by generalising their structure, and in particular the implementation of the knowledge organization systems in the present day information structure of the web environment.
The key standard for the development, application and administration of instruments for information retrieval is the international standard dealing with thesauri and other controlled vocabularies ISO 25964 whose history goes back down to the beginning of the 70ies of the 20th century. The latest edition of 2011 and 2013 (ISO 25964-1:2011, ISO 25964-2:2013) was worked out under the governance of the technical commission ISO/TC 46 Information and documentation. The standard reflects changes brought about by the introduction of information technologies in this field: software applications for the creation and utilisation of thesauri, technology of full-text searching etc. After the original strict focusing upon designing thesauri, the scope broadened with the orientation to more general understanding, as applicable for a wider spectrum of types of controlled vocabularies and other knowledge organization systems. The second part of the standard dealing with interoperability contains separate chapters handling the characteristics of classification schemes, taxonomies, subject heading schemes, ontologies, terminologies, name authority lists and synonym rings. The standard contains both models of processes in form of rules for developing a draft, implementation and administration of thesauri including instructions for solving linguistic and semantic problems, and a structural model of a thesaurus worked out as a conceptual reference model for the implementation of software applications utilising thesauri in a computer environment. The conceptual model is expressed not only verbally in a table, but also graphically in the UML language21. The main classes model the following concepts and their interrelations: thesaurus, the thesaurus concept, the thesaurus term, the relation of hierarchy, the relation of association and the relation of equivalence.
SKOS (Simple knowledge organization system) has been defined by its authors as a data vocabulary for a description of knowledge organization systems allowing their sharing and interconnecting on the web (Miles and Bechhofer, 2009). Its ambition resides in defining the minimum set of characteristics that is shared by all types of knowledge organization systems within the whole span of their scope. In 2009 SKOS was adopted as standard by the W3C consortium and it represents the most important and the most widely used general meta-model of the knowledge organization system in the practice of the present day.
SKOS has the character of an ontology formalised in the OWL language, and as such it is created by classes and their properties (predicates).The basic class is a concept (skos:Concept) that is identified by its URI. Concepts can be aggregated to form conceptual schemes, i.e. knowledge organization systems (the class skos:ConceptScheme serving for their description), such as into thesauri or classification schemes. Another option is joining concepts within the respective system to form collections (class skos:Collection), e.g. into facets or micro-thesauri.
The properties (predicates) of the SKOS language enable the formal expression of the contents of concepts and their correlations. Various types of notes facilitate precise understanding and defining the semantics for human users (skos:definition, skos:note etc.). A group of properties for the designation of concepts enables verbal depicting of each concept (skos:prefLabel – preferred name, skos:altLabel – alternative name, such as synonyms, skos:hiddenLabel – name not imaged) or notation (skos:notation).
The most essential properties are those enabling the description of semantic relations between the concepts (skos:semanticRelation). It is divided in two interconnected groups: relations of concepts within one knowledge organization system and relations of concepts from different systems, called mapping (skos:mappingRelation). Relations of concepts within the context of one system are associations (skos:related), general hierarchy (skos:broader – a broader concept, skos:narrower – a narrower concept) and hierarchy enabling transitivity (skos:broaderTransitive, skos:narrowerTransitive). The course of mapping concepts offers the option of expressing various stages of equivalence: skos:exactMatch, skos:closeMatch. In addition to that also associative relations (skos:relatedMatch) and hierarchical ones (skos:broadMatch, skos:narrowMatch) can be defined between concepts from different systems, and the meaning of such relations is equivalent with analogical relations within one knowledge organization system.
Conclusion
This article is the fruit of our effort to provide a partial contribution to the forming of the theory of conceptual models in the information science. A facet structure of model that is applicable also for the description of conceptual models has been proposed. The application of the perspective of semiotic triangle has served to specify certain selected functions of conceptual models relevant for the information science: creation a model of reality, creation a model of sign, creation of an artefact according to a model, formalization of a conceptual model, creation of a new model with the utilisation of an existing one. A framework typology draft has been developed for the contents and the form of conceptual models in the information science, embedded in the context of conceptual models and modelling languages in computer science.
The introductory part contains the expression of our conviction that the information science is in need of formulating its own theory of conceptual models that will aptly depict the specific objects and events under the scrutiny of this scientific discipline. For the field of descriptive models, the information science needs in particular theoretical foundations enabling the construction of structural models of information sources; especially the digital resources are seen as topical. Another important group of structural models are metadata models and those focusing upon the contents of information sources (aboutness). Descriptive models of processes are required in particular for modelling the communication process, the information needs and the information behaviour. Also the prescriptive models should lean against theoretical foundations. This is preferable especially for a wide circle of models governing the rules for metadata creation as well as for technological and legal models for information retrieval and access to the same.
The formalization of models for the purposes of being applied in machine processing appears to be important in all mentioned fields. We feel that the information science faces its key problem to be solved in finding the optimum ratio of the semantic expressive force of the models on the one hand side and the ease of their utilisation on the other hand side. As shown by numerous examples of tools and languages for knowledge organization, easier solutions often put themselves through in the practice – to the detriment of elaborate and complex systems. It is sufficient to mention the highly formalised system of the Universal Decimal Classification whose complexity hampers its massive usage and (paradoxically enough) may even be a hurdle against its massive application for automatic indexing and in the semantic web environment. Elaine Svenonius (2004, p. 585) concludes her comparison of knowledge theories using words that can be well related also to the problems of conceptual models:”Perhaps we don’t always need a valid representation, when a useful one will do.”
Bibliography
BAWDEN, David and Lyn ROBINSON, 2017. Úvod do informační vědy. 1. vyd. Doubravník: Flow, 2017. ISBN 978-80-88123-10-1.
BRATKOVÁ, Eva and Helena KUČEROVÁ, 2014. Systémy organizace znalostí a jejich typologie. In: Knihovna: knihovnická revue. 25(2), 5–-29. ISSN 1801-3252 (print). ISSN 1802-8772 (online). – English version (Knowledge organization systems and their typology) available from: http://oldknihovna.nkp.cz/knihovna142_suppl/1402sup01.htm or from http://oldknihovna.nkp.cz/pdf/1402sup/142001.pdf .
BUBENKO, Janis A., 2007. From information algebra to enterprise modelling and ontologies – a historical perspective on modelling for information systems. In: John Krogstie, Andreas Lothe Opdahl, Sjaak Brinkkemper, ed. Conceptual modelling in information systems engineering. Berlin: Springer, p. 1–18. doi: https://doi.org/10.1007/978-3-540-72677-7_1 . ISBN 978-3-540-72676-0 (print). ISBN 978-3-540-72677-7 (online).
CABRÉ, M. Teresa, 1999. Terminology: theory, methods and applications. Amsterdam; Philadelphia: John Benjamins Publishing Company. ISBN 978-1-55619-787-1.
COYLE, Karen and Thomas BAKER, 2009. Guidelines for Dublin Core Application Profiles (working draft) [online]. Dublin (Ohio): DCMI, 2009-05-18 [cit. 2018-09-20]. Available from: http://dublincore.org/documents/profile-guidelines/ .
ČERMÁK, František, 2007. Jazyk a jazykověda: přehled a slovníky. 2. dotisk 3. dopl. vyd. Praha: Karolinum. ISBN 987-80-246-0154-0.
ČSN ISO 14721, 2014. Systémy pro přenos dat a informací z kosmického prostoru – Otevřený archivační informační systém – Referenční model. 2. vyd. Praha: Úřad pro technickou normalizaci, metrologii a státní zkušebnictví. 97 p.
ČSN ISO 5963, 1995. Dokumentace. Metody analýzy dokumentů, určování jejich obsahu a výběru lexikálních jednotek selekčního jazyka. Praha: Český normalizační institut. 10 p.
ČSN ISO TR 9007, 1995. Systémy zpracování informací: Pojmy a terminologie pro pojmové schéma a informační základnu. Praha: Český normalizační institut. 131 p.
DROBÍKOVÁ, Barbora, Radka ŘÍMANOVÁ, Jiří SOUČEK and Martin SOUČEK, 2018. Teoretická východiska informační vědy: využití konceptuálního modelování v informační vědě. 1. vyd. Praha: Karolinum. 136 p. ISBN 978-80-246-3716-7. ISBN 978-80-246-3881-2 (pdf).
Embley, David W. and Bernhard Thalheim, ed., 2011. Handbook of conceptual modeling: theory, practice, and research challenges. Berlin: Springer. xix, 589 p. ISBN 978-3-642-15864-3 (print). ISBN 978-3-642-15865-0 (online).
GOGUEN, Joseph, 2005. What is a concept? In: Frithjof Dau, Marie-Laure Mugnier, Gerd Stumme, ed. Conceptual structures: common semantics for sharing knowledge: 13th International Conference on Conceptual Structures, ICCS 2005, Kassel, Germany, July 17-22, 2005. Berlin: Springer, p. 52–77. Lecture notes in computer science, no. 3596. doi: https://doi.org/10.1007/11524564_4. ISSN 0302-9743 . ISBN 978-3-540-27783-5 (print). ISBN 978-3-540-31885-9 (online).
CHEN, Peter Pin-Shan, 1976. The entity-relationship model – toward a unified view of data. In: ACM Transactions on Database Systems. 1(1), 9–36. doi:10.1145/320434.320440. ISSN 0362-5915 (print). ISSN 1557-4644 (online).
ICOM/CIDOC Special Interest Group, 2003. Definition of the CIDOC Conceptual Reference Model [online]. Produced by the ICOM/CIDOC Documentation Standards Group, continued by the CIDOC CRM Special Interest Group. Patrick LeBoeuf, Martin Doerr, Christian Emil Ore, Stephen Stead, ed. Version 6.2.3. © 2003, version from May 2018 [cit. 2018-09-20]. 287 p. Available from: http://www.cidoc-crm.org/Version/version-6.2.3-0 .
IFLA, 2015. Definition of FRBRoo: a conceptual model for bibliographic information in object-oriented formalism [online]. Version 2.4. Chryssoula Bekiari, Martin Doerr, Patrick Le Boeuf, Pat Riva, ed. International Working Group on FRBR and CIDOC CRM Harmonisation, November 2015 [cit. 2018-09-20]. 283 p. Available from: https://www.ifla.org/publications/node/11240 .
IFLA, 2016. Statement of international cataloguing principles (ICP) [online]. Agnese Galeffi, María Violeta Bertolini, Robert L. Bothmann, Elena Escolano Rodríguez, Dorothy McGarry, ed. IFLA Cataloguing Section and IFLA Meetings of Experts on an International Cataloguing Code, December 2016. Edition with minor revisions, 2017 [cit. 2018-09-20]. 26 p. Available from: https://www.ifla.org/publications/node/11015 .
IFLA, 2017. IFLA library reference model: a conceptual model for bibliographic information [online]. Pat Riva, Patrick Le Boeuf, Maja Žumer, ed. Hague: International Federation of Library Associations and Institutions. Rev. August 2017 as amended and corrected through December 2017 [cit. 2018-09-20]. 101 p. Available from: https://www.ifla.org/publications/node/11412 .
ISO 24156-1:2014. Graphic notations for concept modelling in terminology work and its relationship with UML – Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014. 24 p.
ISO 25964-1:2011. Information and documentation – Thesauri and interoperability with other vocabularies – Part 1: Thesauri for information retrieval. 1st ed. Geneva: International Organization for Standardization, 2011-08-08. 152 p.
ISO 25964-2:2013. Information and documentation – Thesauri and interoperability with other vocabularies – Part 2: Interoperability with other vocabularies. 1st ed. Geneva: International Organization for Standardization, 2013-03-04. 99 p.
ISO 704:2009. Terminology work – Principles and methods. 3rd ed. Geneva: International Organization for Standardization, 2009-11-01. 65 p.
ISO/TR 9007:1987. Information processing systems – Concepts and terminology for the conceptual schema and the information base. 1st ed. Geneva: International Organization for Standardization, 1987-07-01. 120 p.
KUČEROVÁ, Helena, 2014. Co analyzujeme při obsahové analýze dokumentů? K pojmu aboutness v organizaci znalostí. In: Knihovna: knihovnická revue. 25(1), 36–-54. ISSN 1801-3252 (print). ISSN 1802-8772 (online). – English version (What do we analyze during subject analysis of documents? The concept of aboutness in knowledge organization) available from: http://oldknihovna.nkp.cz/knihovna141_suppl/1401038.htm or from http://oldknihovna.nkp.cz/pdf/1401sup/1401038.pdf .
LAKOFF, George, 2006. Ženy, oheň a nebezpečné věci: co kategorie vypovídají o naší mysli. 1. vyd. Praha: Triáda. Chapter 2. Od Wittgensteina k Roschové, p. 25–-66. ISBN 978-80-86138-78-7.
LUDEWIG, Jochen, 2003. Models in software engineering – an introduction. In: Software and systems modeling (SoSyM). 2(1), 5–14. doi:10.1007/s10270-003-0020-3. ISSN 1619-1366 (print). ISSN 1619-1374 (online).
MARRADI, Alberto, 2012. The concept of concept: concepts and terms. In: Knowledge organization. 39(1), 29–54. ISSN 0943-7444.
MILES, Alistair and Sean BECHHOFER, ed., 2009. SKOS Simple Knowledge Organization System Reference [online]. W3C Recommendation 18 August 2009 [version, cit. 2018-09-20]. Cambridge (MA): World-Wide Web Consortium. Available from: http://www.w3.org/TR/2009/REC-skos-reference-20090818/ .
NISO TR-06-2017, 2017. Issues in vocabulary management: a technical report of the National Information Standards Organization [online]. Baltimore: NISO, 2017-09-25 [cit. 2018-09-20]. ISBN 978-1-937522-79-7. Available from: https://www.niso.org/publications/tr-06-2017-issues-vocabulary-management .
OMG, 1997. OMG Unified Modeling Language (OMG UML) [online]. Object Management Group, 1997- [cit. 2018-09-20]. Available from: http://www.omg.org/spec/UML/ .
OMG, 2014. MDA guide. Revision 2.0 [online]. Needham (MA, USA): Object Management Group, June 2014 [cit. 2018-09-20]. 15 p. Document Number: ormsc/2014-06-01. Available from: http://www.omg.org/cgi-bin/doc?ormsc/14-06-01 .
OMG, 2017. Semantics of Business Vocabulary and Business Rules [online]. Version 1.4. Needham (MA, USA): Object Management Group, May 2017 [cit. 2018-09-20]. 314 p. OMG Document Number: formal/2017-05-05. Available from: https://www.omg.org/spec/SBVR/ .
PISANSKI, Jan and Maja ŽUMER, 2010a. Mental models of the bibliographic universe. Part 1: mental models of descriptions. In: Journal of documentation. 66(5), 643–667. doi:10.1108/00220411011066772. ISSN 0022-0418.
PISANSKI, Jan and Maja ŽUMER, 2010b. Mental models of the bibliographic universe. Part 2: comparison task and conclusions. In: Journal of documentation. 66(5), 668-680. doi:10.1108/00220411011066781. ISSN 0022-0418.
POPPER, Karl Raimund, 1979. Objective knowledge: an evolutionary approach. Revised ed. Oxford: Oxford University Press. ISBN 0-19-875024-2.
REDMOND-NEAL, Alice and Marjorie M. K. HLAVA, ed., 2005. ASIS&T thesaurus of information science, technology, and librarianship. 3rd ed. Medford: Information Today on behalf of the American Society for Information Science and Technology. xiii, 255 p. ASIST monograph series. ISBN 978-1-57387-243-0. ISBN 1-57387-244-X (with CD-ROM).
RIVA, Pat and Maja ŽUMER, 2018. FRBRoo, the IFLA Library Reference Model, and now LRMoo: a circle of development [online]. Paper presented at IFLA WLIC 2018 – Kuala Lumpur, Malaysia – Transform Libraries, Transform Societes in Session 74 – Impact of recently approved IFLA standards – Committee on Standards. 2018-08-25 [cit. 2018-09-20]. 7 p. Available from: http://library.ifla.org/2130/ .
ROUSSOPOULOS, Nick and Dimitris KARAGIANNIS, 2009. Conceptual modeling: past, present and the continuum of the future. In: Alexander T. Borgida, Vinay K. Chaudhri, Paolo Giorgini, Eric S. Yu, ed. Conceptual modeling: foundations and applications. Essays in honor of John Mylopoulos. Berlin: Springer, p. 139–152. doi:10.1007/978-3-642-02463-4. ISBN 978-3-642-02462-7 (print). ISBN 978-3-642-02463-4 (online).
SEDLÁKOVÁ, Miluše, 2004. Vybrané kapitoly z kognitivní psychologie: mentální reprezentace a mentální modely. 1. vyd. Praha: Grada. 252 p. ISBN 80-247-0375-0.
SVENONIUS, Elaine, 2004. The epistemological foundations of knowledge representation. In: Library trends. 52(3), 571–587. ISSN 0024-2594 (print). ISSN 1559-0682 (online).
THALHEIM, Bernhard, 2011. The theory of conceptual models, the theory of conceptual modelling and foundations of conceptual modelling. In: David W. Embley and Bernhard Thalheim, ed. Handbook of conceptual modeling: theory, practice, and research challenges. Berlin: Springer, Part V, p. 543–577. doi:10.1007/978-3-642-15865-0_17. ISBN 978-3-642-15864-3 (print). ISBN 978-3-642-15865-0 (online).
WAND, Yair and Ron WEBER, 1990. Toward a theory of the deep structure of information systems. In: Janice I. DeGross, Maryam Alavi, Hans J. Oppeland, ed. Proceedings of the Eleventh International Conference on Information Systems, December 16–-19, 1990, Copenhagen, Denmark. Baltimore (Mar.): ACM Press.
ZENG, Marcia Lei and Jian QIN, 2016. Metadata. 2nd edition. Chicago: Neal-Schuman, an imprint of the American Library Association. xxvii, 555 p. ISBN 978-1-55570-965-5.
1 BOX, George Edward Pelham, 2013. An accidental statistician: the life and memories of George E. P. Box. Hoboken: Wiley, p. 162. ISBN 978-1-118-40088-3.
2 In the Czech context this is confirmed by the recently published publication of the authors' team of Institute of Information Studies and Librarianship FF UK (Drobíková, 2018).
3 Therefore, the map of the fictional Yoknapatawpha county, which was created by William Faulkner, can also be considered as model. Preview of the image is available from: http://en.wikipedia.org/wiki/File:Yoknapatawpha.County.jpg [cit. 2018-09-20].
4 Cited according to PALEK, Bohumil, ed., 1997. Sémiotika: Ch. S. Peirce, C. K. Ogden and I. A. Richards, Ch. W. Morris, H. B. Curry. 2. přeprac. vyd. Praha: Karolinum, p. 37. ISBN 80-7184-356-3.
5 Note: An extreme example of individually created models are some sketches in Leonardo da Vinci's notebooks, who even deliberately wrote comments in mirror-writing to them (see e.g. preview on http://www.bl.uk/manuscripts/Viewer.aspx?ref=arundel_ms_263_f001r [cit. 2018-09-20]).
6 See e.g. Catalogue of the competition designs on http://wwwold.nkp.cz/soutezni_navrhy/start.htm [cit. 2018-09-20].
7 Commercialy available e.g. from: https://beta-rdatoolkit-org.ezproxy.is.cuni.cz/RDA.Web/Guidance?externalId=en-US_Recording_methods [cit. 2018-09-20].
8 Note: The same applies for data model – this phrase can also designate both model of data and model consisting of data.
9 Note: At this level of generalization it can be stated that the abstract conceptual model has the same qualities as the expression entity from the FRBR, resp. IFLA LRM model.
10 Note: At this level of generalization it can be stated that the concrete conceptual model has the same qualities as the manifestation entity from the FRBR, resp. IFLA LRM model.
11 Forward and reverse engineering differ in the course of development. Forward engineering goes from model to artefact, while during reverse engineering we derive the model backwards from the functioning implementation.
12 Note: Czech equivalent for Library reference model has not yet been coined. More translation options are available: referenční model knihovny, knihovní či knihovnický referenční model, eventually referenční model pro knihovny.
13 See files RDA element sets, online available from http://www.rdaregistry.info/Elements/, and RDA value vocabularies , available from http://www.rdaregistry.info/termList/ .
14 Metadata Management Associates, 2010. Element sets [online]. In: Open metadata registry, 2010– [cit. 2018-09-20]. Available from: http://metadataregistry.org/schema/list.html .
15 Available from http://www.rdaregistry.info/termList/RDAContentType .
16 ISO 5127:2017. Information and documentation – Foundation and vocabulary. 2nd ed. Geneva: International Organization for Standardization, 2017-05. 353 p.
17 ISO/IEC 2382:2015. Information technology – Vocabulary [online]. 1st ed. Geneva: International Organization for Standardization, 2015-05 [cit. 2018-09-20]. Available from: https://www.iso.org/obp/ui/#iso:std:iso-iec:2382:ed-1:v1:en .
18 KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online databáze]. Praha: Národní knihovna České republiky, 2003– [cit. 2018-09-20]. Available from: http://aleph.nkp.cz/cze/ktd .
19 IFLA, 2010. Multilingual dictionary of cataloguing terms and concepts (MulDiCat) [online]. MulDiCat Working Group, Cataloguing Section; Barbara B. Tillett, ed. Hague: International Federation of Library Associations and Institutions, 2010– [cit. 2018-09-20]. Available from: https://www.ifla.org/publications/multilingual-dictionary-of-cataloguing-terms-and-concepts-muldicat , and from: http://metadataregistry.org/vocabulary/show/id/299.html .
20 Universitätsbibliothek Basel, 2013. BARTOC.org: BAsel Register of Thesauri, Ontologies & Classifications [online]. Projektleiter Andreas Ledl. Basel: Universitätsbibliothek Basel, 2013– [cit. 2018-09-20]. Available from: http://www.bartoc.org/ .
21 Preview available from http://www.niso.org/schemas/iso25964/Model_2011-06-02.jpg [cit. 2018-09-20].







{kind=link}
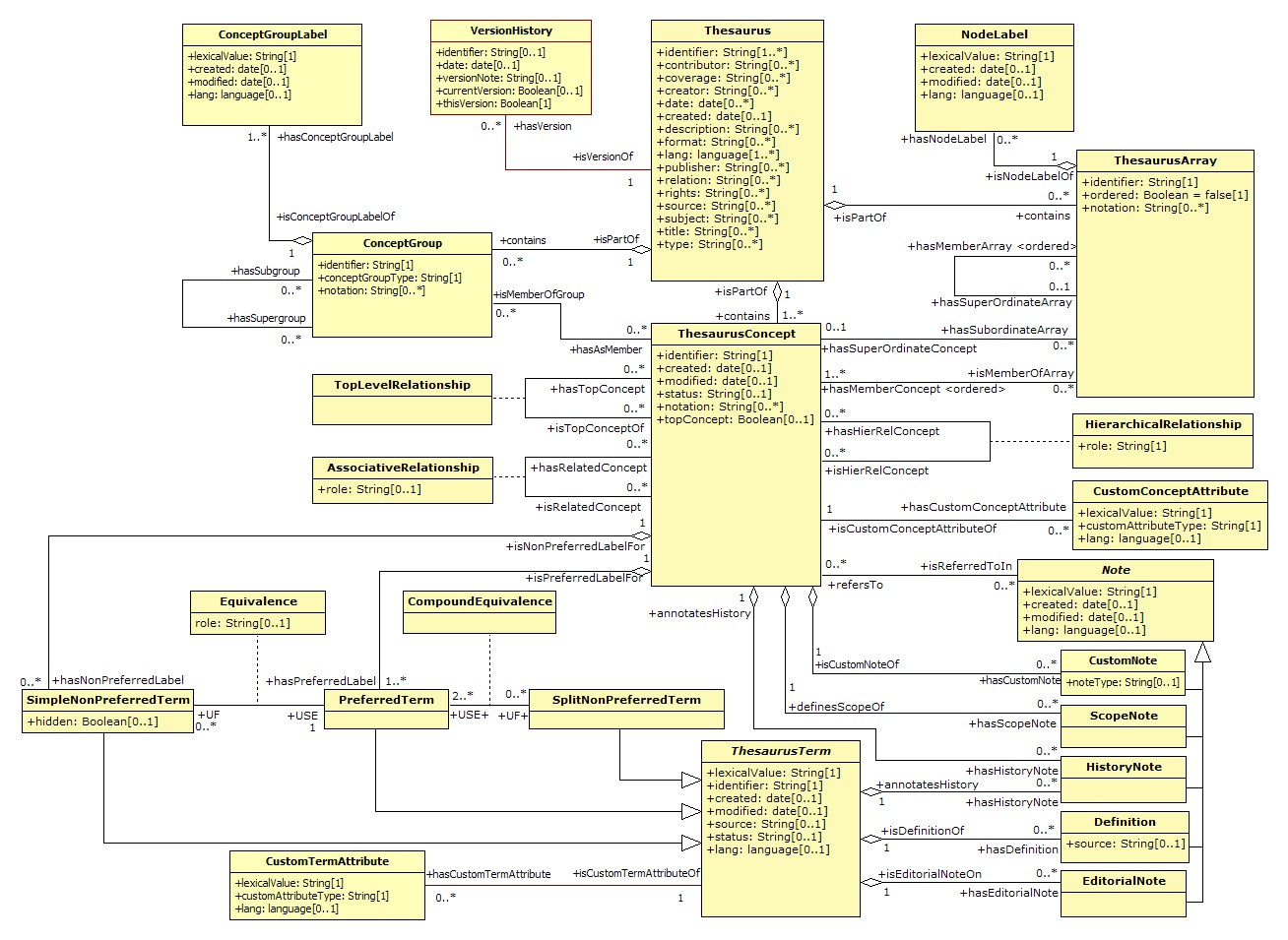{kind=link}