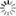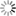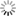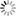Towards issues of descriptive metadata for knowledge organization systems
Keywords: Knowledge organization systems, metadata description, metadata elements, NKOS Application Profile, FRBR conceptual model, knowledge base
PhDr. Eva Bratková, Ph.D., PhDr. Helena Kučerová, Ústav informačních studií a knihovnictví FF UK v Praze (Institute of Information Studies and Librarianship, Faculty of Arts, Charles University in Prague)
Introduction
The present study covers the problems of metadata description of knowledge organization systems. It follows in the footsteps of the preceding study published in 2014[1] that dealt with issues of their typology. The determination of the type of a knowledge organization system (acronym KOS) is one of the important parts of the metadata description. The new study is based upon a typical set of KOS records processed within the prototype of a knowledge base that is being developed within the „Knowledge base for the subject area of knowledge organization“ project, as part of the NAKI Programme“ (DF13P01OVV013). One of the objectives of the research has been to develop the concept and the contents of KOS description so as to comply with the aim and function of the knowledge base. The collection of metadata representing the given KOS has shown the necessity to describe them as entities of strongly variable character, from the very beginning over the continuous changes down to their present day presentation, in freely accessible structures of linked open data. First of all the study presents the results of the analysis of the existing metadata KOS description in some selected databases and then it offers a draft of their description in the knowledge base. It is founded upon the general principles of FRBR and FRSAD conceptual models, and also upon the proposal of metadata elements for the KOS description within the NKOS Application Profile (NKOS AP), as prepared by the DCMI Networked Knowledge Organization Systems Task Group. The proposed metadata schema takes account of further existing metadata schemas that are in use for similar purposes (BARTOC, DCAT, DC-terms, FRBR/FRSAD, OMV, Schema.org, and TaxoBank).
The text of the study is divided into three parts. The first covers the results of the analysis and the evaluation of the KOS descriptions in the existing practice of the bibliographic databases as well as the known KOS online registries. The second part presents a draft of a standard for the KOS description within the DCMI NKOS Task Group. The summaries of these two parts form the starting point of the third chapter offering a proposal of the description of these systems in the project knowledge base for the field of information and knowledge organization. The draft of description is complemented with a few selected examples of the chosen KOS types (classification scheme, thesaurus, subject headings) of the knowledge base, with appended diagrams.
1 Existing practice of knowledge organization systems description
This part of the study submits the results of the analysis of a number of KOS metadata descriptions, as applied in diversified available online databases. The evaluation intends to focus upon the description of these systems in certain selected bibliographic and catalogue databases, assessing them on the level of all sorts of other publications, yet of course particularly in the specialized registries or databanks describing exclusively KOS. The quantity and the character of applied elements (data) are subject to evaluation.
1.1 Description of knowledge organization systems in bibliographic or catalogue databases
The knowledge organization systems (classification schemes, taxonomies, thesauri, ontologies etc.), especially in their traditional forms, are currently described in bibliographic databases of national registration agencies, and also in databases of local and union catalogues. Due to all sorts of reasons the mentioned types of databases need not always observe the completeness of the registered KOS (such as KOS produced by commercial entities as grey literature), possibly only a fraction is saved, or they are not registered at all. Also KOS in online form are registered, some of them accessible free of charge, some under a licence. There is little or no representation of KOS in various structures of linked open data in the catalogues of the present day. Mapping KOS records in the above mentioned types of databases has confirmed the anticipation that the catalogue records do not offer suitable representation of these systems for the project of knowledge base. Due to similar considerations they are apparently not applied in the systems incorporated into the environment of the semantic web. They are of no use also with regard to the smaller number of descriptive data, including the fact that their structures do not support the present day communication and utilization.
However, the bibliographic and catalogue databases have served a good purpose in the research project, namely as resources for establishing the existence of KOS and for taking over their identification data. The acquired data, anyway, had to be checked, unified and complemented by further KOS-specific data, taking into consideration the given research objectives. Down to the present day more than 230 records were stored into the knowledge base, representing almost 100 important KOS[2]. The subject of ascertainment were both KOS that were published in various intervals on paper carriers, and KOS that are published by electronic media, beginning with the form of CD-ROM, over the access in the online regime, down to the novel free access in form of rich structured linked open data.
Especially the ascertaining of the existence of KOS on the traditional paper carriers or solid electronic ones has been found as a demanding task. In this case the research team implemented the excerption work with the maximum possible aid of the union catalogue WorldCat, combined with the national bibliographic databases, and possibly also with the national union catalogues[3]. In the cases of absence of KOS records in the chosen databases, or if they were described minimally or controversially, also further resources had to be consulted in the information search. Especially literature about concrete KOS was checked, whether any; KOS records in traditional forms were consulted, but rather in the digitized ones (permanently kept, e.g., in HathiTrust Digital Library, Internet Archive.org and similar systems). Also KOS records available in the Google Books system since 2012 were monitored for verification, although they have been taken over from the WorldCat database thanks to their free location in the new structure „Schema.org“.
As mentioned above, catalogue records that used to be stored, as a rule, in a MARC type format, doubtlessly lack the sufficient volume of data (see Fig.1), as necessary for the research project objectives. Some specific data are missing (such as information about the KOS type, its internal structure, the number of lexical units etc.) They bear no explicit indication concerning the type of KOS and this disables its automatic searching. But for a few exceptions, the records are provided with no abstracts or annotations. KOS that can look back at a long development usually lack indications about the necessary relationships between the versions – it is difficult to trace down the editions, especially if they were combined with changes of titles or of features. In most records unifying data are missing, namely indications of the Uniform title or Author-Title. Such data greatly facilitate online search. But for minor exceptions, however, unambiguous and permanent identifiers of works or expressions thereof[4] are missing. An advantage, on the other hand, tends to be the relatively good quality of KOS alternative titles, data concerning their edition or version, the respective language and country of publication. The catalogue records of KOS and their particular elements in the traditional MARC format (including MARCXML or MODS format) have static character, which makes them unsuitable for the dynamic linking in the environment of semantic web.
|
>040 GEBAY $e rakwb $b ger $c GEBAY $d OCLCQ >015 05,N36,0101 $2 dnb >016 7 976026287 $2 DE-101 >020 3598116519 >020 9783598116513 >080 >084 AN 93550 $2 rvk >049 CQKA >245 00 Dewey-Dezimalklassifikation und Register : $b DDC 22 / $c begr. von Melvil Dewey. Hrsg. von Joan S. Mitchell. Hrsg. von Der Deutschen Bibliothek. >246 3 DDC 22 >250 Dt. Ausg. >260 München : $b Saur. >515 Erschienen: 1 - 4. >630 07 Dewey-Dezimalklassifikation. $2 swd >650 07 Inhaltserschließung. $2 swd >650 07 Bibliothek. $2 swd >650 07 Klassifikation. $2 swd >650 07 Übersetzung. $2 swd >651 7 Deutsch. $2 swd >655 7 Richtlinie. $2 swd >700 1 Dewey, Melvil. >700 1 Mitchell, Joan S. >710 2 Deutsche Bibliothek (Frankfurt, Main; Leipzig) >730 0 Dewey decimal classification and relative index. $l Deutsch. >856 41 $3 Inhaltsverzeichnis $u http://bvbr.bib-bvb.de:8991/F?... >029 0 GEBAY $b 7716793 |
Fig. 1 Record (OCLC 643133344) of the German translation of the 22nd edition of Dewey Decimal Classification in MARC Text Area format (without encoded fields 00X) from theWorldCat;the record contains the uniform title of expression level (OCLC, 2015) in field 730
The catalogue records stored and communicated in format of the MARC type, and namely even if converted to some of the formats of linked open data, contain, at the present day, only a certain basic set of descriptive data covering KOS that have been used within the research project. These are: title data of descriptive or formalized character, creator data in authority forms, edition or version data (very useful in case of KOS), publisher data, permanent identifiers, such as URI, ISBN a ISSN, number of pages in case of paper carriers, subject description in form of notations, usually some of the universal classifications (DDC, UDC, LCC etc.) or terms from controlled vocabularies, series data, sometimes even rather rich annotations, possibly also location of items in libraries or other information institutions.
1.2 Descriptive metadata of KOS within Schema.org
The context of information under part 1.1 can also lead to the analysis and evaluation of a KOS description integrated in one of the novel metadata schemas, and namely Schema.org (with name space http://schema.org/, see xmlns: schema; rdf fomat declaration in Fig. 2), as based on experience of the OCLC network with the records of their union catalogue WorldCat. At the present day, this schema is used globally for the need of open accessible Linked Open Data (LOD) that can describe anything (the terminology of the schema talks about describing „things“) and, accordingly, also information resources including KOS. A short introduction will be given upon the basis of freely accessible linked data about KOS, as provided by the WorldCat database and kept as microdata (Microdata Section) in RDFa structure, as well as on the web site of displayed catalogue records under HTML code. The OCLC network, having been among the first to make its catalogue records available in this way, has chosen Schema.org[5] for this purpose. Thus an enormous effect has been achieved – the catalogue information can reach the end users very quickly, in particular those who receive them via their mobile equipment, and namely using the Google search engine[6], after the data have been transferred also to the Google Books system.
A comment is needed prior to the presentation of the applied elements of the metadata schema, and namely by highlighting the fact that the concept does not reside in a „classical“ (static) description of the resources wherein appropriate values of properties are assigned to the resources conforming to the given description elements. In the LOD concept the assigned values are linked with values in free-accessible controlled vocabularies, or direct linking with values of these vocabularies can be achieved with the help of the URI identifiers. Schema.org enables dynamic generation of a description of a certain resource with the aid of the combination of different elements joined within the defined basic object categories (work, event, action, organization, person, place, product, intangible thing etc.).
The knowledge organization systems, as presented under LOD in the WorldCat database, comprise the unambiguous identification of the record (URI) within the introductory designation of type of the described resource in the element <schema:about> – see Fig. 2 (the first occurrence of the element „rdf:Description“). The unique number of the record in the WorldCat database has been made use of. The database as such is identified by the aid of element <void:inDataset> from another name space „VoID“ (http://rdfs.org/ns/void#).
The basic data of the described KOS can be introduced as a description of some of the types of CreativeWorks. For instance the type Book (http://schema.org/Book) is at our disposal – this type is valid also for the KOS in print form. With the help of element <schema:bookFormat>, however, a partial form can be specified, such as the form Electronic book (http://schema.org/EBook), under which also the online available web is organized at the present day – see Fig. 2. No finer categorization for the KOS description requirements is at our disposal yet. The main title of KOS can be indicated within the element <schema:name> and other titles in the element <schema:alternateName>. It is suitable to specify both types of titles, in addition to that, by the internal attribute of the language code of the title. If a uniform title of the work is at hand, it will be indicated directly as part of the description of the Work (http://schema.org/CreativeWork) within the element <schema:name>. In this respect Schema.org reflects the concept of the FRBR model.
Edition data relating to KOS can be indicated in the element <schema:bookEdition>, the publisher´s name in the element <schema:publisher> and the date of publication in the element <schema:datePublished>. If the respective KOS is a continuing resource (web etc.), also the element <schema:startDate> is applicable, and namely within the description of the object Event of publication (http://schema.org/PublicationEvent), including the place of the respective event, in element <schema:location> and the organizer, i.e. the publisher, in the element <schema:organizer>. The publisher (as well as the corporation having created this KOS) can be also described by name, in addition to that, in the element <schema:name> as part of the description of the Organization object (http://schema.org/Organization). Much the same also the place of publication can be described by name within the description of the Place (http://schema.org/Place). The place of publication by way of code can be implemented upon the basis of the already existing vocabulary of places (http://id.loc.gov/vocabulary/countries) within the framework of element bearing the same name <dcterms:identifiers> from name space „dcterms“ (http://purl.org/dc/terms/). The language of the resource can be indicated by code in element <schema:inLanguage> with link to the chosen code list (such as http://id.loc.gov/vocabulary/iso639-1). Permanent identifiers ISBN can be indicated in element <schema:ISBN> within the description of the object category Product Model (http://schema.org/ProductModel).
If the creators of KOS are persons, also their names can be used for the description within the description of the object Person (http://schema.org/Person), and namely not only the mentioned element <schema:name>, but also more detailed elements <schema:familyName>, <schema:givenName>, <schema:birthDate> or <schema:deathDate>. Both names of persons and those of corporations exist already in large numbers of the VIAF system database, comprising unique identifiers VIAF ID, and possibly also the international identifiers ISNI.
The subject description of KOS (and also other materials) can be implemented in particular upon the basis of linking to the values of a great number of knowledge organization systems (such as controlled vocabularies), and namely within the object category Intangible (thing) (http://schema.org/Intangible). Examples can be seen in Fig. 2. Records from the WorldCat database can be linked, e.g., directly with classifiers of the Dewey decimal classification on the server http://dewey.info (e.g. http://dewey.info/class/025.431/), or the controlled subject terms of the now accessible OCLC in the new FAST system (for instance the subject term „Classification, Dewey decimal“ is now freely available on the OCLC server of linked data (http://experimental.worldcat.org/fast/863693/)[7]. The schema has a prepared element <schema:abstract> for the text of abstract or annotation– see example in Fig. 2.
Fig. 2 Online record of database WebDewey (permalink http://www.worldcat.org/oclc/49510336) from the WorldCat database in form of linked open data (rdf.xml) (OCLC, 2015, the elements are marked by yellow colour, whereas their values are blue)
At the present day the metadata schema Schema.org does not yet enable the description of specific features of KOS (the type of KOS, the internal relationships within KOS, KOS structure etc.). The same holds true also for other specific types of resources. However, the schema is being further developed, attention is paid to various details initiated by a number of communities interested in the description of „things “. An extensive activity focussing upon the field of the description of information resources is developed by the working group SchemaBibEx (https://www.w3.org/community/schemabibex/), under the leadership of OCLC expert Richard Wallis. Suggestions are welcome by way of email or chat communication.
1.3 Descriptive metadata of KOS in the BARTOC registry
This part presents the results of our analysis of the KOS description in the BARTOC[8] registration system. Its typology of KOS was discussed in the above cited study[9] already. The registry has been operated since 2013 and in August 2014 its database contained 667 records. In April 2015 the number of registered systems almost doubled (1 137 records).
Each KOS in the BARTOC registry base is described with only one record, as regards description level. The description unit is the system as a whole, irrespective of the carrier or format, highlighting its present day form, especially the electronic one, as well as online approach. The historical development relating to the form of continuous registering of the printed products and those on CD-ROM has not been implemented; at the time being only some records include short abstracts covering briefly the development. The KOS description is not based upon the FRBR model. This concept is due to the main objective of the registry – providing the users quickly with clearly arranged information about the existence of the respective KOS. That is why the overall number of metadata elements is not large, most values being permanently stored in structured vocabulary – term taxonomy[10]. The advantage of the registry consists in that the records, in addition to the online system, are freely available also in more formats as open linked data. Up to 20 languages can be used for the online communication with the BARTOC registry (language equivalents concern even a number of values of descriptive data).
The free documentation of the BARTOC registry has not yet opened access to the metadata specification used for the description of included systems. That is why the following commentary can be based only upon the presentation form of the metadata records displayed within the frame of the online search system, taking into account metadata localized in the accessible records in the rdf.xml structure. An example of the description of the popular AGROVOC thesaurus can be found in Fig. 3.
Each metadata record in the BARTOC registry comprises always one unique and permanent record identifier (URI) playing an important role for any linking. When viewing the record via an Internet browser, URI appears within the address (e.g. the AGROVOC thesaurus has URI http://www.bartoc.org/node/305). If the record is represented in linked data structures, then an appropriate extension is added to the basic URI (http://www.bartoc.org/node/305.rdf, http://www.bartoc.org/node/305.xml etc.). Component parts of the record are also data about the time of the record creation (Date created) and of updating (Date modified). Whereas these technical metadata are not displayed in the course of online searching, they are comprised in the linked data records, and namely through the mediation of the metadata defined by Dublin Core specifications with the attribute of data type, such as:
<dc:created rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">
2013-09-10T15:34:42+02:00</dc:created>
<dc:modified rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">
2014-08-12T14:27:30+02:00</dc:modified>
Each record indicates a unique Title of the KOS as one whole, having the obvious character of a „uniform“ title. Its shape in the language of the described system (such as „Dewey Decimal Classification“, „Gemeinsame Normdatei Online“, „Kielitieteen ontologia“) is determined by the producer of the registry according to his own decision. Some titles include also a geographic complement in round brackets, exceptionally the title may comprise also an acronym without separation by any punctuation mark (e.g. „JITA Classification System of Library and Information Science“). Also alternative titles can be indicated under which the user can seek them. These can be abbreviations or acronyms (such as „DDC“, „EuroVoc“ etc.), in another case the producer can have chosen the full official title as an alternative (such as „The Life Science Thesaurus“ for the known commercial thesaurus „Emtree“, here in the role of a uniform title).

Fig. 3 Record of the AGROVOC thesaurus in presentation format in the registry BARTOC.org (in the selected English version of language communication, 2015)
The element Author contains mostly the names of companies and organizations bearing responsibility for KOS. For example in a DDC record (http://www.bartoc.org/node/241) the „Online Computer Library Center (OCLC)“ stands in the place of author, whereas the actual author M. Dewey is only briefly mentioned in a short abstract. If there is any, then the name of author is usually joined by way of hyperlink within the element VIAF with records from the VIAF database through the URI whose component part is the unique VIAF identifier (VIAF ID), e.f. hyperlink http://viaf.org/viaf/156508705 identifies the above mentioned OCLC centre.
The element Link is intended for linking the record with the web site describing the respective KOS, or from which KOS is accessible online. The link to the web site of the AIMS portal, from which the AGROVOC thesaurus is accessible, can be seen in Fig. 3. The record of the EuroVoc thesaurus contains a link leading to its main home page (http://eurovoc.europa.eu/).
Subject data range among the very valuable information in the short record of the registry. Also an Abstract in English is included. It bears informative character, containing diversified information about the field of application of KOS, its development, but sometimes also about the number of its units at the present day. The values of the known multilingual thesaurus EuroVoc are well suited for use in the part Topic. The URI identifiers of the descriptors of the EuroVoc thesaurus are shown together with the basic record. A major advantage of the registry resides in organizing the records with the help of the DDC scheme in the DDC element (used up to the third hierarchical level). The classifiers, again, are part of the actual taxonomy of the terms (such as the value „630“ for agriculture is indicated in URI (http://www.bartoc.org/taxonomy/term/10622). However, linking with the records to the freely available online database DDC (http://dewey.info) has not been implemented yet.
Part of the formal data of the record is the element Access to KOS that is understood in the legal sense of the word. Simple values are used that are, again, component parts of the actual taxonomy of the terms, such as „Free“ (http://www.bartoc.org/taxonomy/term/1377 ) or „Registered “ (http://bartoc.org/taxonomy/term/17). The element Format of KOS can contain up to three types of values (they are also part of the taxonomy): on the one hand the form of access (printed, online, CD-ROM etc.), on the other hand format designation (RDF, XML etc.) or also the structure (such as OWL, SKOS etc.). The last and substantial element is the element KOS Type, making use of the values of its own defined BARTOC typology. The number of types has been seen to increase from five (August 2014) to 6 at present (the type „Glossary“ has been added recently). The types are also parts of taxonomy (the type „Classification“ has URI http://www.bartoc.org/taxonomy/term/3 ). The own taxonomy of terms comprises also values for the element KOS Language) (e.g. URI http://www.bartoc.org/taxonomy/term/10747 belongs to the French language). As far as it exists, the record of the BARTOC registry is also additionally linked via hyperlink with the article of the English version of Wikipedia (in principle, however, this relates to a bibliographic reference concerning the system).
1.4 KOS descriptive metadata in the TAXOBANK registration databank
Yet another concept of KOS descriptive metadata focusing upon the scope and the contents is represented by the registration databank TaxoBank[11] that has been operated since 2009. It is administered by an expert team of „taxonomists“ of a private American company „Access Innovations“, specialized in providing services in the field of software applications with particular focus in the linguistic aspects of data stored in databases. The records of this registration databank contain very detailed and extremely well structured data about „controlled vocabularies“, i.e. knowledge organization systems[12]. The databank gets complemented irregularly and suggestions for KOS registration can be sent also by current Internet users, but each record is then processed by a specialist. About 250 of knowledge organization systems are registered as of today.
The TaxoBank has not opened the metadata specification in its public documentation, either. That is why also the following commentary is based upon records displayed in the presentation format in the frame of the online search system. An example of a rather short description of the known AGROVOC thesaurus can be found in Fig. 4. A longer description is represented, e.g., by a record of an important American agricultural thesaurus NAL[13].
|
http://www.taxobank.org/content/agrovoc-thesaurus AGROVOC Thesaurus Thu, 2009-11-19 08:42 — aii_admin AGROVOC is a multilingual, structured and controlled vocabulary designed to cover the terminology of all subject fields in agriculture, forestry, fisheries, food and related domains (e.g. environment). The AGROVOC Thesaurus was developed by FAO and the Commission of the European Communities in the early 1980s. Since then it has been updated continuously by FAO and local institutions in member countries. Vocabulary type: thes Vocabulary Sample URL: http://aims.fao.org/agrovoc/page?c=12332 Was vocabulary created as a course project: 0 Type of display: alph, html, diag, perm, other Relationship types: eq_pri_eq, hier_bn, rel_t, ont Characteristics Comments: "AGROVOC Linked Open Data (LOD) is a project to turn the AGROVOC thesaurus into a multilingual, terminological backbone for agricultural digital goods. Hosted by research partner MIMOS it provides web-accessible, structured data records on agricultural concepts and even more importantly, links those concepts to other online thesauri." Availability Comments: available also via webservice Import/download instructions : See http://aims.fao.org/website/Download/sub ▼ Provider Vocabulary provider name: FAO Provider URL: http://www.fao.org/ Provider contact details: "National organizations and institutes are welcome to help enrich and maintain AGROVOC's many languages by joining our growing community. Please contact us at http://aims.fao.org/contact" Provider section comments: "The Food and Agriculture Organization of the United Nations leads international efforts to defeat hunger. Serving both developed and developing countries, FAO acts as a neutral forum where all nations meet as equals to negotiate agreements and debate policy. FAO is also a source of knowledge and information. We help developing countries and countries in transition modernize and improve agriculture, forestry and fisheries practices and ensure good nutrition for all. Since our founding in 1945, we have focused special attention on developing rural areas, home to 70 percent of the world's poor and hungry people." |
|---|
Fig. 4 Record of AGROVOC thesaurus in presentation format in databank TAXOBANK (2015)
The metadata record from TaxoBank has been identified by record identifier (URL). When viewing via Internet browser the value gets displayed in the address. An example of URL record, as described by the AGROVOC thesaurus, is shown in Fig.4 (first line).
The main bloc of descriptive information comprises the unique Title for KOS; also in this case it is determined by the experts of the system, following their internal rules. In some KOS the TaxoBank and BARTOC registry are identical (e.g. „Dewey Decimal Classification“), some other KOS accept considerable differences when determining uniform titles (cf. for instance „NAL Agricultural Thesaurus“ and „United States Department of Agriculture Thesaurus“). The shown records contain also a few system data, and namely Date and time of processing the record (e.g.: Wed, 2009-11-11 11:08) and Editor of the record. This can be a full name of a person or his/her code (e.g.: Barbara Gilles; aii_admin etc.). Such data are complemented with a brief Abstract (see Fig. 4), sometimes also in form of a quote from the documentation of the given KOS. The abstract can comprise various information about the origin of the KOS and its founder, about the present day owner or operator, the character of KOS and the determination of the user community, the access forms, etc.
The bloc of General information can include a larger amount of information. Also in the case of this registry all known Vocabulary alternative name or acronym can form part of it. In the record of the above mentioned Agricultural thesaurus the editors have indicated various alternative values: „NAL Thesaurus“, „Agricultural Thesaurus“ and „NALT“. The element Vocabulary type falls under the substantial mandatory data. The values are given by the internal code list and indicated in form of an abbreviated term, such as: clsssys (classification scheme), thes (thesaurus), subjh (subject headings), taxon (taxonomy), concmp (concept map), contrvoc (controlled vocabulary), gaz (gazetteer), glos (glossary) and ont (ontology). Further, as far as known, it is possible to indicate the name of Author or Editor of KOS, including his/her exact role, such as: „Lori Finch, Thesaurus Coordinator“. The databank records also further very valuable data that are typical for the given KOS, if available. These are Current version/edition, e.g.: 2009 Edition, Current version date, e.g.: Wed, 2008-12-31, Update frequency, e.g.: Annually, Available formats, e.g.: XML, SKOS, PDF, MARC, TXT etc. (also in the case of this registration both the concrete metadata formats and the specifications of their structures can be encountered side by side). Two indicative values „0“ or „1“ are registered in a specific element using the form of a question (Was vocabulary created as a course project). As far as available, the element Vocabulary URL of the KOS with free access will contain the address on which the system is available, such as: http://agclass.nal.usda.gov/. Especially in the case of commercially available KOS a very interesting element is Vocabulary Sample URL, for instance a sample of data from the CAB Thesaurus (http://www.cabi.org/cabthesaurus/mtwdk.exe?yi=sample).
Some of the records are provided with specific and very useful information, and namely in the bloc Scope and Usage. These are Languages that are used for the KOS terms (the values are indicated in English, such as „English“, „Spanish“ etc.), further subject elements Major subjects covered and Minor subjects covered. The actual values are also in English and it can be supposed that they have been taken over from the own controlled vocabulary of the producer, such as: Agricultural subjects, biological sciences // Rural and agricultural sociology; physical sciences. The purpose of the described KOS can be registered in form of a shorter or longer text, and namely within the element Purpose, and possibly also the intended user communities of the KOS can be indicated in the element Used By. Another valuable information is the link to Related vocabularies; for instance in the record of the already mentioned NAL Agricultural thesaurus this element contains the information of the existing related NAL Glossary, including details of its contents and the number of collected terms. Some very specific information require experts for qualified coverage; these are, e.g., data registered in the elements Overlap with related vocabularies and Mappings to other vocabularies. The respective data have verbal form.
Quite a lot of valuable information, especially numerical and encoded, is registered in the elements of the bloc Vocabulary characteristics. If the information is known, then the element Description of overall structure can serve for presenting, in URL form, the document describing the overall structure of KOS. The element Type of terms can contain detailed information about the type of terms handled in KOS, such as: „Agricultural and scientific concepts“, „Concepts in the domain of medicine and related domains, expressed in professional medical and scientific terminology“ etc. The element Type of display, appreciated by professionals, can contain detailed facts about displaying the involved terms. The TaxoBank databank uses fixed determined values from its own list in form of abbreviated expressions, such as: hier = hierarchical, alph = alphabetical, perm = permuted, html, other. Similarly, in the element Relationship types, detailed information about the relations among the terms can be registered (again in form of abbreviated values), such as: eq_pri_eq = equivalence, eq_lang = language equivalence, hier_bn = hierarchy of genus, hier_inst = class of instance, rel_t = association, othr = others). If available, the elements Number of classes indicate data about the number of classes of the given KOS (e.g.: 16 top terms in hierarchical display, 109 hierarchies of descriptors etc.), the total Number of terms (e.g.: English: 73,194, Spanish: 69,118), Number of preferred terms (e.g.: English: 44,857; Spanish: 44,857), Number of Non-Preferred terms (e.g.: English: 28,337; Spanish: 24,261), or alto Depth of Hierarchy with numerical marking of the classification levels within the hierarchy (e.g.: 11 levels). The record can contain also the element Characteristics Comments with notes of verbal type, such as about the project to convert the terms into the structure of linked open data.
Variegated data concerning the options of utilizing knowledge organization systems, especially of commercial character, can be found within the framework of elements of the bloc Terms and Conditions. Simple English expressions from the own list can be used for registering, under the element Availability, the degree to which KOS is accessible, for instance „free“ etc.. More detailed notes can be given by text in the element Availability Comments. Under the element Licensing Options details can be given, again in form of English text, about conditions for acquiring the respective KOS user licence. As an extra, the element Import/download instructions can serve for introducing URL addresses enabling the download of data.
The following last bloc Provider registers, under the element Vocabulary provider name, the name of the company administering and providing the described KOS at the present day. At the time being the names under which companies appear are not unified; sometimes a full name including acronym can be found, sometimes the acronym only, such as: „Online Computer Library Center (OCLC)“, „FAO“ etc. Under the element Provider URL the URL address of the given company can be added, and the element Provider contact details is another place for further useful information in text form. The last element Provider section comments can also comment upon the activities of the provider in verbal form.
2 Descriptive metadata of the NKOS Application Profile
The analysis of the present practice of KOS metadata descriptions in the preceding chapter has shown the description in the TaxoBank databank to be the richest, having the greatest number of elements, being very comprehensive and including, in some instances, even larger verbal descriptions. The introduction of certain specific elements is inspiring (such as the type of relationships within KOS, the art of displaying the terms or of mapping KOS into other knowledge organizing systems). This part of the study is going to present another metadata description involving also a number of specific descriptive elements, but in addition to that it has been developed upon the FRBR conceptual model, i.e. it offers a hierarchically stratified KOS description on a plurality of levels – pertaining to one work – including its optional multiple expressions, and also manifestations (publications). Its description has been included into this chapter as an important metadata schema under preparation, shared by an international team of experts; actually, it exists in the stage of project at the time being.
The KOS metadata description is being prepared within the framework of the comprehensive Dublin Core Application Profile, DC-AP NKOS[14][15] for the knowledge organization systems as well as for NKOS Vocabularies [16] that are being developed since 2010 by DCMI/NKOS (Dublin Core Metadata Initiative / Networked Knowledge Organization Systems Task Group)[17]. The application profile is founded, to a very large extent, upon DCMI Metadata Terms (http://purl.org/dc/terms/), including the basic DCMES set (http://purl.org/dc/elements/1.1/). Also the utilization of the adms name space is envisaged (http://www.w3.org/ns/adms#), as well as dcat (http://www.w3.org/ns/dcat#), frbrer (http://iflastandards.info/ns/fr/frbr/frbrer/) and wdrs (http://www.w3.org/2007/05/powder-s#).
The newly designed standard has specified elements that are indicated in the following, and namely on three descriptive levels. For describing the knowledge organization system on the „Work“ entity level (in Czech „Dílo“), its name Title <dct:title> is suggested as the substantial element. A closer specification has not yet been determined, but the title should be unique (for instance a uniform title) and it ought to be in the original language. The VIAF database already contains a number of uniform titles (within the frame of the future clusters) with the unique identifier VIAF ID, such as „UMLS“ (http://viaf.org/viaf/176304810), „Gemeinsame Normdatei“ (http://viaf.org/viaf/215300162), Library of Congress Classification (http://viaf.org/viaf/203733980), Library of Congress Subject Headings (http://viaf.org/viaf/211744653) etc.
The proposed element Identifier <dct:identifier> should identify the given work in an unambiguous way. The utilization of identifiers of the VIAF system for the work (VIAF ID) appears to be the optimum solution, but on the level of scientific works only few identifiers of this type are available at the present day (VIAF ID see record in Fig. 5). Yet another option would be identification with the help of the international identifier of textual works (ISTC)[18], however, as shown by the ISTC database, identifiers of textual works of KOS type have not yet been assigned. The element Description <dct:description> has been prepared for various types of text communications (abstract, contents, graphic representation or practically any text describing KOS as a work). An important formal element suggested by the DCMI NKOS Working Group is the element Type of KOS <dct:type>. The values for this element have already been determined within the application profile in a specific structured vocabulary[19]. The element Creator <dct:creator/dc:creator> is intended for the name of the person or corporation who is primarily responsible for the creation of the resource (work). The formal element Rights <dct:rights> is prepared for text information specifying various authorship rights relevant to the resource. A subject description of the work can be formulated within the element Subject <dct:subject>. Both the utilization of freely created terms, and of the range of already existing controlled vocabularies are envisaged (such as classification schemes or thesauri), as prepared for linking within the frame of the semantic web. Concerning the description of the work also the element Date <dct:created> is taken into account and could be used, primarily, also in the sense of the actual date of creation. In case such historical information may not be available, it can be replaced with the date of expression or manifestation (publishing) of the work. It is recommended to use the standard etry of date according to the standard ISO 860, or profile W3CDTF. There is yet another formal element, and namely the specific element Audience <dct:audience> (determination of the community utilizing a specific KOS) and also a fully novel element Used by <nkos:usedBy>, to be defined in the name space (http://purl.org/nkos/). It is intended for the name of the agent (programme, application) utilizing the KOS being described. The last group of the designed elements has been assigned to relationships between single KOS (on the level of the work). The following elements have been designed: Relation <dct:relation>, intended for linking with the related KOS through the mediation of unambiguous data (identifier, in the optimum case), and further Is part of <dct:isPartOf> that is intended for linking with the KOS whose component part is the described resource (again with the aid of unambiguous data); Is based on <nkos:isBasedOn> is intended for linking with a resource that is in some way related with the described one. A specific relationship is represented by the element Supporting documentation <wdrs:describedBy> whose value can comprise the citation of resources that also describe the resource in question, also in the respective sense.
Fig. 5 Three-level (hypothetical) record of the most recent Czech online edition of UDC (Universal Decimal Classification) in the suggested metadata schema AP-NKOS
The element Title<dct:title> has been also suggested on the level of the „Expression “ entity (in Czech „Vyjádření“). Its closer specification has not yet been determined, either, yet the option of adding complementary data within the frame of the title has been mentioned, in particular data concerning the edition or the KOS language. It can be expected that the title of the expression should also be unique. Also in this case a number of such formalized titles have already appeared in the VIAF database, such as thanks to the initiative of the Library of Congress and the German National Library, e.g. „Universal decimal classification. Selections. Czech” (http://viaf.org/viaf/186352368) or „EUROVOC“ (http://viaf.org/viaf/215952972). The example of record in Fig. 5 bears the uniform title for the online Czech version of UDC, as hypothetically prepared according to the examples of titles from the VIAF database. Temporarily, at the time being, the same example bears the value „unspecified” in the element Identifier <dct:identifier>. It is anticipated that this value will appear in the VIAF system in the course of time. The projected formal element Contact <dcat:contactPoint> is ensured by the DCAT domain. The value of the element can consist in the reference to the place where further information can be provided about the expression of the work (about the translation, the form of publishing etc.). The element Description <dct:description> is also available on the level of expression. It is prepared for text communication (abstract, contents etc.), describing the process of expression of the work (translation, edition etc.). The element Creator <dct:creator/dc:creator> is present on the level of expression as well and it ought to comprise names of persons or corporation bearing responsibility for the expression of the work (translator, editor of the online version etc.). A substantial formal element on the level of expression in the case of text works and, accordingly, also KOS, is the element Language <dct:language>. This concerns the language of the text and it is recommended to make use of the language code lists. The present day practice of a number of systems consists in utilizing freely available language vocabularies on the server of the Library of Congress. The record in Fig.5 bears the URI of the language (three digit code) in this element from the cited vocabulary. Genuinely specific and valuable data of the KOS records concerns the size (number of terms). That is why the suggested AP NKOS specification involves the element Size note <nkos:sizeNote>. Naturally, the description of the expression takes into account the element Date <dct:created> – it will bear, as far as known, the date of termination of the expression (completion of translation etc.). Newly, however, the element Date (modification) <dct:modified> has been incorporated. The standard entry of date according to ISO 860, or W3CDTF profile, is recommended. Also on this level of description a legal element has been integrated as Rights <dct:rights> for text information stipulating various types of property rights connected with the expression of the work (such as authorship translation right etc.). The level of expression, too, can bear the formal element Audience <dct:audience> (specifying the community authorized for the utilization, e.g. of the KOS translation – see Fig. 5) and also the element Used by <nkos:usedBy> (see information indicated above). A novelty on this level is the definition (again the own name space had to be used, namely nkos:) of a specific and valuable element KOS Frequency of update <nkos:updateFrequency>. It is recommended to take over the values from the DCMI Frequency vocabulary (http://dublincore.org/groups/collections/frequency/). The group of suggested elements for the relationships of one KOS to another (on the level of expression) contains mostly the same elements as the level of work: The element Relation <dct:relation> is intended for linking with the corresponding expression of KOS through the unique entry (Fig. 5 shows links to other language online versions of the given classification), a new element of the frbr name space: Is realization of <frbrer:isRealizationOf>, intended for unambiguous reference to the realized work (optimally the URI of the work), further the element Is part of <dct:isPartOf>, intended for linking with the expression of the KOS, the described resource being its component part. The specific relation is again represented by element Supporting documentation <wdrs:describedBy>, whose value can comprise the citations of resources that describe the expression being described, also in the subject sense of the word. A new formal element (from the adms: domain) is the element Sample (adms:sample), that ought to contain a reference to web with demonstration versions of KOS, with examples of records of these KOS, especially in a case when the resource is commercially available, or the resource gets available after registration (see Fig. 5).
The last level of KOS description „Manifestation“ (in Czech „Provedení“), i.e. concrete products, is ensured by the last group of elements. The element Title <dct:title> should contain the descriptive title of the published KOS. The example of record in Fig. 5 bears the title of the online product in Czech. In case a plurality of titles exist (alternative titles) the suggested specification has not made use of the Dublin Core element „dct:alternative“ and at the present moment it has not been clearly specified where the alternative titles ought to be entered. The element Identifier <dct:identifier> can bear the known identifiers of both printed and electronic products (ISBN, ISSN, DOI, URI, URN and others). The formal element Contact <dcat:contactPoint> is defined in the same way as on the level of expression. Also the element Description <dct:description> is available, and namely for the purpose of text entry with further details about the character of the given product. The element Creator <dct:creator/dc:creator> is present also on this level of description and with the same meaning. A novel element is an important one, and namely Publisher <dct:publisher/dc:publisher>, intended for the name of a corporation or person publishing KOS or its concrete version/edition. KOS specific information is related to format and physical carrier. For this purpose the element Format <dct:format> has been designed; for online products it is recommendable to use the respective values from the MIME vocabulary (Internet Media Types, IMT, http://www.iana.org/assignments/media-types/media-types.xhtml). For the purpose of publications a new element has been defined Date (issuance) <dct:issued>. Also on this level of description an element has been included relating to rights to the published KOS, and namely Rights <dct:rights>. A novel element is one from the own name space Services offered <nkos:serviceOffered>, indicating types of services that are open to users (downloading, annotation, querying etc.). A group of elements serving for relations between single KOS (on the level of manifestation) comprise also mostly the same elements as the level of work and expression: element: Relation <dct:relation> is intended for linking with related KOS publications, element Is part of <dct:isPartOf>, is intended for linking with a KOS publication whose component part is formed by the resource being described. There is a novel element, again from the frbr name space: Is embodiment of <frbrer:isEmbodimentOf> that is intended as an unambiguous reference to the expression of the work (optimally URI of expression). A specific relation is represented by element Supporting documentation <wdrs:describedBy> and element Sample (adms:sample).
3 Proposal of KOS metadata description in the knowledge base of knowledge organization
3.1 Description schema in the knowledge base
The goal of the NAKI project is to assemble and to systemize the current body of knowledge in the field of knowledge organization in form of a knowledge base that enables saving, browsing and searching the existing entries and deriving new knowledge. The knowledge base will be made accessible in the format of linked open data and will serve for further research and as an education tool in the field of information science and librarianship. The ontological structure of the knowledge base consists of two types of knowledge units: 1) statements („pure knowledge“ – sentences formalized as logical predicates and instantiated in form of text data) and 2) descriptive metadata covering relevant document and non-document resources (persons, institutions, events, tools, activities and processes). The introductory phase of knowledge acquisition has supplied material for a prototype of knowledge base with about 2 300 units of declarative knowledge: 150 statements in the RDF format, a glossary with the scope of 200 terms, 1 000 records of scientific literature, 230 records of knowledge organization systems. The KOS description creates an important set of knowledge entities in the second module of the knowledge base represented by descriptive metadata.
The framework methodology for the design of the KOS descriptive metadata was chosen according to the recommendation of the Guidelines for Dublin Core Application Profiles[20]. In accordance with that the first to be delimited were functional requirements relating to metadata in the knowledge base whose point of departure were general requirements to the knowledge base as a whole: 1) enabling the assembling and systemizing of domain knowledge concerning KOS, taking account of the local cultural and language specific aspects of the Czech environment, 2) enabling access to the existing knowledge and deriving new knowledge in the format of linked open data, 3) providing resource material for the preparation of an original Czech monograph, 4) supplying resources for updating the Czech terminology, 5) enabling utilization for the education in the field of information science and librarianship. These requirements have lead to the conclusion that the metadata in the knowledge base should contain the most comprehensive description as well as include the depiction of history and the mutual relationships between different KOS.
The second step was the creation of a domain model with the purpose of delimiting the entities (objects, things) to be described by metadata. Its diagrammatical illustration can be found in Fig. 6. Of course the key entity is the Knowledge Organization System, another important one is Agent; in our approach a person or an institution is represented that is connected with KOS, be it as creator, operator or user. The design of the knowledge base is founded upon the principle of maximum reuse of proven concepts and models. Accordingly, already on the level of domain model it contains the customized entities of the FRBR and FRSAD models Work, Expression, Manifestation, Person, Corporation and Thema[21] and their relationships. The three entities Work, Expression and Manifestation represent a mutually interconnected and logically structured set of data about the KOS. The last essential component part of the model is the entity Theme that has been directly taken over from entity Thema of the FRSAD model and covers data about the subject contents of KOS.
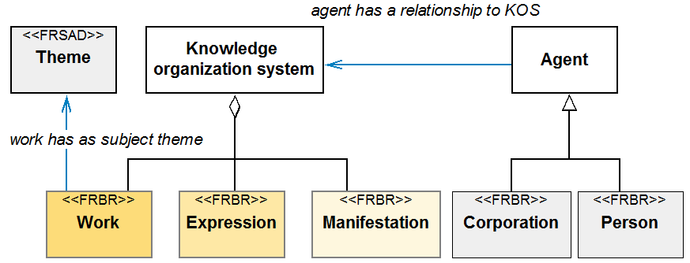
Fig. 6 Domain model, based upon the FRBR and FRSAD models
The structure of metadata description in Figs. 6 and 7 is illustrated with the help of class diagram in the UML (Unified Modelling Language), used in accordance with ISO 24156, governing the use of UML notation in the terminological work[22]. The data elements are arranged in groups that are linked with semantic relations. Association stands for any semantic relationship by way of a line ending with an arrow in case of asymmetrical association. Aggregation stands for a partitive hierarchical relationships („is a part“), the respective arrow ending with a diamond. Generalization represents a generic hierarchy with inheritance („is a type“), its arrow ending with a triangle pointing from the subordinate class („subtype“) to the superior class („supertype“).
After the construction of the domain model the following stage defined properties of the respective objects and specified their relationships; the resulting structural model of metadata description is diagrammatically represented in Fig. 7. Again we applied all efforts to make use of all elements of description that had been defined as well as standardized vocabularies. The main resource was the NKOS Application Profile, as described in the preceding part. 11 out of its 21 elements have been directly applied in the knowledge base, 6 elements have been mapped with various degrees of equivalence and 4 elements have not yet been applied (update frequency, rights, audience, services offered). In addition to the descriptive elements of NKOS AP also two of its value vocabularies (NKOS Vocabularies[23]) have been utilized: the KOS Relation-Type Vocabulary has been taken over to the full, and the KOS Types Vocabulary[24] has been reflected in the typology of knowledge organization systems[25]. Our own typology has been complemented with the classification of KOS types that has been taken over from the Classification System for Knowledge Organization Literature[26], specifically from part 0 – Form Divisions, classes 01, 03 and 04. Further value vocabularies have been appropriated for the element language (at the present day a three-character code and names according to ISO 639-2 are in use), format (format codes under the MIME standard are used), role (here the vocabulary of the Library of Congress is used[27]). Identifiers have been appropriated from the following name spaces: VIAF ID for persons and corporations and, rather exceptionally, for works and expressions, ISNI for persons and corporations, ISBN, ISSN, DOI, URL, URN and URI for manifestation.
There are 3 types of classes in the structural model of metadata description in Fig. 7: «entity», «agent» and «code list». Classes of the «entity» type correspond with entities from the 1st group of the FRBR model – Work, Expression and Manifestation. Also the semantics of their relationships has been taken over from the FRBR model – the work is realized with the help of expression, whereas expression is embodied in the manifestation. The classes of the «agent» type correspond with entities from the 2nd group of the FRBR model, responsible for the contents, the production, the distribution or administration of entities of the 1st group. The classes of the «code list» type are authority lists of permissible values that are related to the properties of classes of the types «entity» and «agent». An important role among the code lists is played by the class Theme; in the sense of the FRSAD model this is a generalization of entities of the 3rd group from the FRBR model, pertaining to the subject contents of the work. The relationships between single themes can be also defined (typically either hierarchy or association); in the model this is depicted by the recursive association relationships of themes. The association classes Relationship and Role of the agent reflect the situation when the properties relationship type and role are not properties of single classes, but properties of the relationships between them.

Fig. 7 Structure of KOS metadata description in the knowledge base
In addition to the classes representing data elements there are also two so-called abstract classes in the model – Entity and Agent. Both are so-to-say parent classes in the generic hierarchy possessing no instances of their own, but all their properties and relationships are inherited by their hierarchically subordinate children classes Work, Expression, Manifestation, Person and Corporation. The way generalization is construed in UML enables to define in one place (in the parent class) the properties and relationships occurring to the same or similar extent in a plurality of objects, which enables reducing redundancy within the model. For instance identifier, or the declaration „it has an identifier “ in the class Entity on the implementation level concerns both the work and the expression and manifestation, while the semantics in each of these classes is domain specific. Some inherited features can get modified in the children classes. The property description in the children classes is specified both by its name and is contents – specific requirements for the KOS description are determined on the level of the work (description of work), on the level of expression (description of expression) and on the level of manifestation (description of manifestation). The same is valid for the abstract class Agent. All its properties and relationships are inherited by classes Person and Corporation where a specification of property takes place, namely the property of name gets more closely specified as name of corporation, name and surname of person.
Both the work, and the expression and manifestation can be related with mutual relationships of certain type (e.g. Work A is based on Work B, Expression A has been mapped into Expression B, Work A describes Work B). Such reality can be captured by the recoursive associative relationship of entities. It has been already mentioned that inheritance concerns not only the attributes of parent classes, but also their relationships. Specifically, the relationship agent has a relationship to the entity on the implementation level is applicable as a relationship between a person and the work, between a corporation and the manifestation etc., where the concrete role of a given agent in a given extent is determined by the value of the element role from the code of roles (such as author, publisher, editor, provider).
3.2 Definition and mapping of data elements for the description of KOS in the knowledge base
The following review offers elements of description, as derived from class attributes defined in the structural model (see Fig. 7). The structure of metadata description in Fig. 7 has been slightly simplified for better clarity. Some data elements from the structural model have been additionally structured internally for the purpose of entering data into the knowledge base: language (code, name), availability (description, type), type (own code list – Classification System for Knowledge Organization Literature), type of relationship (relationships of entities, relationships of concepts/terms). Each element of description is complemented with the definition of its meaning and examples of possible values.
ENTITY
Abstract class, supertype for classes Work, Expression, Manifestation. Generalizes properties that are common for all children classes.
identifier
Supertype for the identifier of work/expression/manifestation. Each entity has an identifier. Examples: URI; URN; ARK; VIAF ID; ISBN; ISSN; DOI; URL
title
Supertype for the title of the work/expression/manifestation. Each entity has 1 title.
Examples: Dewey Decimal Classification; EUROVOC
alternative title
Supertype for an alternative title of the work/expression/manifestation. Each entity can have more alternative titles (especially abbreviations/acronyms, possibly titles in other /equally valid languages, or Czech translation).
Examples: DDC; Dewey Decimal Classification
description
Supertype for the description of the work/expression/manifestation. Each entity can have a description.
Examples: abstract; annotation; structured contents
date
Supertype for the date of creation of the work/expression or publishing of the manifestation.
Examples: 2013-01-12; 1876-00-00; 2015
RELATIONSHIP
The class serves for specifying the mutual relationships of the entities (relation Entity – Entity, Work - Work, Expression – Expression, Manifestation – Manifestation), semantic relationships of concepts (relation Theme – Theme) and types of relationships expressed in KOS (relation Expression – Relationship).
Relationship type
Value from the own code list of relationships. The code list comprises the types of entities as well as semantic and syntactic relationships between the units that can be represented by the given KOS (mutual relationships between KOSs as well as between their structural parts).
Examples: concepts/terms relationships: generic hierarchy; association; relationships of entities: summarisation; adaptation; complement; based on; whole-part
THEME
Keyword
Keywords from the own controlled vocabulary delimiting the domain / field / theme covered by KOS, and possibly the domain (contents, field, subject matters) of the organized units.
Examples: knowledge organisation (scientific discipline); agriculture; medicine
Definition
Verbal expression of the contents and the scope of a concept.
Example: The discipline of knowledge organization investigates the process of organizing knowledge and its context, i.e. resources that are transformed in the course of organization, methods used as well as tools and products created by this process, including the participating actors – persons, institutions, technologies
Facet
Facet used for the organization of the glossary.
Example: process
WORK
Description of work
Subtype of description of the entity. Verbal characteristics of the contents of the work in a natural language. It comprises the description of the conceptual foundation of the given KOS, the history, information about updating, information about the creators, purpose, determination of users.
Type
Value from the own code list of types of knowledge organization systems.
Example: ontology; thesaurus
Type (KOL)
Notation of the Classification System for Knowledge Organization Literature (KOL). KOS is described by classmarks from the part 0 – Form Divisions, classes 01, 03 and 04.
Example: 042 Universal Decimal Classification
EXPRESSION
Description of expression
Subtype of entity description. Verbal characteristics of the contents of expression in a natural language. It comprises information about the edition/version, about the structure of the whole system, of the structure of headings/records (descriptors, codes), of the linguistic form of terms, explanation of the notation system, display, browsing and search options.
Number of units
Number of units (lexems) within KOS.
Examples: 15 000 classmarks; 20 953 descriptors
Language
Indication of language under ISO 639-2.
Name of language
Name of language under ISO 639-2 (Czech version).
Examples: German; Arabic; Dutch
Code of language
Code of language under ISO 639-2.
Examples: ger; eng
MANIFESTATION
Bibliographic citation
Bibliographic citation of manifestation under ISO 690.
Example: DEWEY, Melvil, devised. Abridged Dewey decimal classification and relative index. Ed. 15. Ed. by Joan S. MITCHELL, Editor in Chief, Julianne BEALL, Rebecca GREEN, Giles MARTIN, Michael PANZER, Assistant Editors. Dublin (Ohio): OCLC, 2012. lxvii, 1228 s. ISBN 978-0-910608-81-7. ISBN 0-910608-81-4.
Description of manifestation
Subtype of entity description. Verbal characteristics of the contents of manifestation in the natural language. Comprises information about the format of the given manifestation, the way of display and possibly further physical characteristics of the resource (e.g. access to the resource).
Resource reference
Reference to the place wherefrom the described KOS is available (e.g. URI or URL).
Example: http://id.loc.gov/authorities/classification
Availability
Characteristics of the access to the resource.
Availability-description
Verbal characteristics of how the resource can be accessed (free text).
Examples: In: NK ČR (ABA001) – for reference only; NK ČR Knih. Inst. (ABA003) -- sign. Od 20.817, from 20.818, Od 549/B1, Od 549/B2; Library Jinonice (ABD(107).
Availability-type
Value from the own code list of availability types.
Example: open access
Format
Value from the own code list of formats (subset of MIME (IMT) vocabulary).
Examples: application/rdf+xml; text/html
Medium
Value from the own code list of media.
Examples: CD ROM; online
Structure
Value from the own code list of structures.
Example: SKOS
AGENT
Abstract class, supertype for classes Person and Corporation. A class generalizing entities from the 2nd group of the FRBR model (Person, Corporation), bearing responsibility for the intellectual or artistic contents, physical production and distribution or administration of entities in the first group.
Name
Supertype for the name and surname of person, name of corporation.
Identifier VIAF
Permanent identifier (ID VIAF) of an agent in the VIAF database (Virtual International Authority File). Source: http://viaf.org.
Identifier ISNI
Permanent identifier (ID ISNI) of an agent in the ISNI database (International Standard Name Identifier). Source: http://isni.org.
PERSON
Name of person
Subtype of name of agent.
Surname of person
Subtype of name of agent.
CORPORATION
Name of corporation
Subtype of name of agent.
ROLE OF THE AGENT
Role
The role of agent with respect to his relationship to the entity. Value from the own code list of roles. Mapped into the vocabulary MARC Code List for Relators (http://id.loc.gov/vocabulary/relators)
Example: author (of work);translator (expression);publisher (manifestation)
The most recent implemented stage of the design of elements for the KOS metadata description is their semantic mapping into the relevant name spaces. The already mentioned functional requirements for the accessability of the contents of the knowledge base in the form of linked open data resulted in the necessity to suggest the elements of KOS description so as to fulfil, as far as possible, the parameters of the so-called five-star schema[28] of data openness. The latter determines that the respective data shall be linked with other related data with the help of references. Eight name spaces were chosen to serve this purpose – in the preceding part of the study already described schemas of the registries. BARTOC and TaxoBank, NKOS AP and Schema.org. In addition to these systems also the generally applicable DCMI Metadata terms (DC-terms) and FRBR and FRSAD models and the specialized schemas DCAT and OMV have been integrated.
Data Catalog Vocabulary (DCAT)[29] is a recommendation of the W3C Consortium, approved in January 2014. It contains the schema and the vocabulary for metadata description in the dataset catalogues. An example is the EU Open Data Portal (http://open-data.europa.eu/en/data/). The DCAT schema is relevant for the linking of data from the knowledge base due to the fact that the present KOSs as linked data have the character of a dataset. The nature of the vocabulary is markedly eclectic; it brings only 7 own descriptive elements (the web page from which the dataset is accessible, contact, URL for access, URL for downloading, size in bytes, type of medium, key word). Although its authors do not designate DCAT as a Dublin Core application profile, they take over the DC elements to a considerable extent and, as a rule, they usually complement the general definition with specific comments for the purpose of describing datasets. The DCAT schema can be considered as a certain analogy of NKOS AP. Whereas the primary purpose of NKOS AP is the description of KOS in their online registries, DCAT is intended for describing datasets in their online catalogues.
OMV (Ontology Metadata Vocabulary)[30] is the result of an international project having been implemented in 2004–2009 by the OMV Consortiumm consisting of: University Bremen and its Center for Computer Technologies, Madrid Polytechnical University, University of Karlsruhe and the Stanford Center for Biomedical Informatics Research. Its goal consists in creating a formal metaontological framework for the description of applied ontologies from the viewpoint of knowledge representation. The output of the project is an open-acces metadata vocabulary for a uniform description of ontologies (OMV Core Metadata Entities and OMV Extensions). It contains a list of description attributes (such as Work, description, date of creation), arranged in 13 classes. The key class is ontology, further classes are persons and organizations developing it, and also classes for closer characterization of the given ontology: license model, knowledge representation paradigm, type of ontology, formality level, ontology task being solved, domain, applied methodology, tools applied, syntax, ontology language. For some attributes (such as type of ontology) lists of values are available. As suggested by name, OMV is a metadata schema specialized for ontologies. At the present day they are considered to be the most progressive type of KOS. Its contribution consists in defining elements of description that are ontology specific and cannot be found in other, more generally conceived schemas (such as formality level, paradigm of knowledge representation used, methodology of ontological engineering applied, the ontological language in use). An interesting aspect of OMV resides in that it focuses attention primarily upon the conceptual base, without concentrating upon describing ontology in form of a document filled with instances.
The results of mapping descriptive elements of KOS are arranged in the table in Fig. 8. It can be stated that the authors succeeded to map each of the descriptive elements at least into one relevant namespace. The 7 elements creating the core of the general identifying descriptive data have been mapped in all chosen systems. Along with the justification of the semantic linkability of the suggested elements of description this mapping brought also impulses to add further potentially applicable elements from the relevant name spaces which do not form part of our schema at the time being and whose integration can be considered in the future, namely: purpose, utilization, user determination, rights, offered services, updating frequency,way of display, formality level, ontology language, applied knowledge representation paradigm.
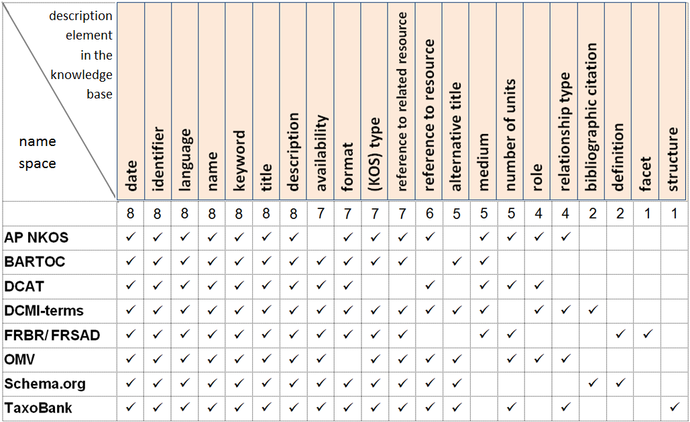
Fig. 8 Mapping elements of description of KOS in the relevant name spaces
Metadata schema application examples for KOS description in the knowledge base
The basic structural elements of metadata description have been again depicted by way of a class diagram in the UML laguage. The key structural component parts of each description are the three entities used from the FRBR model – Work, Expression and Manifestation. The relationship Work – Expression is designated by the association realizes, whereas the relationship Expression – Manifestation by the association embodies.
Fig. 9 Scheme of links between thesaurus and subject heading scheme in the knowledge base
The example in Fig. 9 is a graphical representation of the description structure of two KOS: Library of Congress Subject Headings (LCSH, VIAF ID of the work: http://viaf.org/viaf/211744653/) and thesaurus AGROVOC (a VIAF ID has not yet been assigned to the work). Both systems are described on the level of work (D1 and D2), expression (V1, V2 and V3) and manifestation (P1, P2, P3, P4 and P5). In the case of LCSH the situation of one work, one expression in form of linked open data and one manifestation have been depicted. With the utilization of the relationship P4 is part of P1 has enabled the description of manifestation also on a finer level of granularity. The manifestation of P1 is a whole, i.e. the complete headinglist, whereas the manifestation P4 LCSH-Heading, describing the heading „Feudalism“, is its part. The FRBR model would obviously enable also an alternative solution of this relationship: single headings could be considered as separate works that are the component parts of another work, i.e. the subject heading scheme. However, such solution in the case of very comprehensive KOS with tens or hundreds of thousands of units would be rather wasteful and a structured description of headings on the level of work, expression and manifestation would result in considerable redundance. An analogous line work – expression – manifestation, again down to the level of single entries (D2 – V3 – P3 – P5), has been illustrated in the case of the AGROVOC thesaurus in the form of linked open data. The manifestation P3 AGROVOC-LOD is available in three data formats (HTML, turtle and RDF), as shown by way of the economic technique of generalization enabling to relate the information about available formats not only to the whole thesaurus, but also to its single descriptors. As concerns the AGROVOC thesaurus in the LOD form, its administrator executed selective mapping into the LCSH (specifically covering 1 075 decriptors from the group Generalities), as depicted by association semantic mapping between the manifestations (records) P5 and P4. The description of the AGROVOC thesaurus comprises in this case, in addition to the expression in the LOD form, also the description of the historically first version of the thesaurus (V2) in printed form that was published in seven volumes in 1982 (P2). The mutual relation of these two expressions is illustrated by the association V3 is based on V2. The third work (D3) in this example is a conference paper whose topics is thesaurus AGROVOC (the diagram in Fig. shows this work in simplified form as one object, aggregated with the expression and the manifestation). The association D3 is about D2 is an example of implemenation of a concept from the FRBR model stating that the theme of the work can be anything, i.e. also some other work. This example allows us to notice two ways of expressing the mutual relationships of KOS.The first option is a direct and explicit expression of a work - work relationship (D3 is about D2), epression - expression (V3 is based on V2) or manifestation - manifestation (P5 is mapped into P4). The second option of expressing is indirect, ensuing from inference: works D1 LCSH and D2 AGROVOC are related due to the fact that their single manifestations or even parts thereof are mutually mapped.
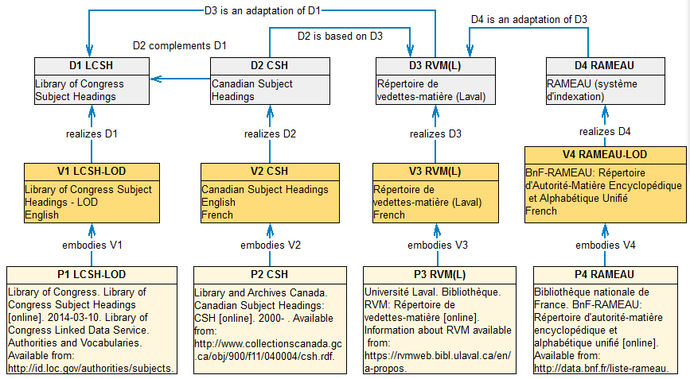
Fig. 10 Scheme of links between some subject heading schemes in a knowledge base
The example in Fig. 10 demonstrates the possibility of capturing, with the help of construction elements from the FRBR model, often very intricate relationships between the knowledge organization systems. The diagram shows four independent systems of subject headings – Library of Congress Subject Headings (D1 LCSH), Canadian Subject Headings – D2 CSH), Subject headings of the Library of Laval University in Quebec (D3 RVM(L)) and the French subject heading scheme RAMEAU (D4) (http://viaf.org/viaf/202974143). The relationships between the contents of these systems are as follows: RVM(L) was established in 1946 by translation of a part of LCSH from English to French, whereupon this translation was complemented in the follow-up by adding further headings reflecting Canadian life and institutions. The RVM(L) is the foundation of the CSH that is available in English version form the 60ies of the 20th century and was further complemented to its bilingual (English and French) form. The CSH subject heading scheme is in use in the Canadian libraries in parallel with LCSH reflecting Canadian life and institutions. By way of adapting the Canadian RVM(L) subject heading scheme the French RAMEAU was founded. These facts are represented by four association relationships: D3 is an adaptation of D1, D2 is based on D3, D2 complements D1 a D4 is an adaptation of D3. In this example an alternative of representing the relationships between four subject heading schemes upon the highest level of generality has been chosen – the relationships are defined on the level of work. Another possible variant of description could be an entry of the same relations (adaptation, based on, complement) on a finer level of granularity, i.e. between concrete expressions or even between manifestations, possibly between a manifestation and a work or between a manifestation and an expression.

Fig. 11 Scheme of classification links and of a subject heading scheme in a knowledge base
- The example in Fig. 11 shows the structure of description of two products of the Library of Congress – Library of Congress Subject Headings (D1 LCSH) and Library of Congress Classification (D2 LCC, http://viaf.org/viaf/203733980). The LCSH subject heading list is described in its commercial version this time, made accessible within the frame of the Classification Web portal, and namely down to the level of single entries (the relationship P6 is part of P1 expresses that the subject heading „Classification, Universal decimal“ with the identifier „sh85026810“ is part of LCSH Headings). A component part of the portal is also the LCC classification. The fact of both KOS being integrated in the Classification Web portal is depicted by the relationships P1 is part of P5 and P2 is part of P5. In the case of LCC classification further two forms of expression have been captured – V3 is the static PDF and MS Word format with free access, V4 describes LCC in the format of linked open data. The format enabling free acces to the linked data is registered in the facetes data format and data structure that can be combined with each other.
Conclusion
In the course of collecting data about the knowledge organization systems the hypothesis was confirmed that classical cataloguing practice using the MARC type formats and proceeding in accordance with the existing rules (such as AACR etc.) is not satisfactory for the purpose of KOS description in the context of the projected knowledge base. The existing proprietary solutions of KOS description (for instance the TaxoBank system) are certainly interesting and inspiring, but the public has not been offered the relevant metadata specifications and documentation. That is why the hypothesis of the applicability of the theoretically conceived FRBR and FRSAD models and of the NKOS AP application profile has been tested. However, both cases showed very high abstractness of these models; prior to actual implementation in a concrete software environment a thorough analysis is indispensable and they also must be complemented by own specifications. Filling the thus created metadata structure with concrete data has already brought practical experience and enabled defining some problematic aspects. The FRBR model is intellectually demanding, as concerns the determination of how various entities on the highest level should be filled. Problems appear as early as at the moment of defining identifiers and forms of titles for the work and the expression, generally accepted names and identifiers, for instance in the VIAF system, being very scarcely available. Yet another problem consists in deciding how to reasonably split the data in the elements description and date in the entities work and expression, for avoiding useless redundancy. This issue is connected with the general problem of how to separate the contents (the work) and the form (the expression), and it requires being solved separately in each case of description. Additional problems are brought by the decision-making whether the described unit should be considered as a new work or expression. The application of general principles formulated in the FRBR study often suggests a plurality of solutions and tends to be affected by many factors in the practice. By way of example: is it more appropriate to consider all editions of the AGROVOC thesaurus as one work, or are the differences between the 1982 edition and the present version, after having been re-worked to ontological structure[31] and linked open data format, so conspicuous as to require considering them as two different, althought interconnected works? How should we proceed in the case of various types of editions of the Universal Decimal Classification? Should „UDC Summary” in 52 languages be handled as 52 expressions? What should be held for the decisive criterion determining that the case in question is a specific expression of UDC – the language, the edition or the type (full, medium, abridged etc.)?
A specific problem is related to the use of the entity „Thema“ of the FRSAD model for expressing the contents of KOS. The knowledge organization systems often fall into the category of multidisciplinary works wherein the theme is usuall expressed according to formal viewpoints in the practice (e.g. UDC is classification, LCSH is a subject heading scheme, and even cases of the type DDC is Dewey decimal classification are not rare). Naturally, such approach would lead to duplicities in the knowledge base; the theme described in this way would overlap with the determination of the KOS type. After all, this is confirmed also by the FRSAD study that is using for such data the term „isness“, in that it is nor considered as the determination of theme, but as one of the attributes of the resource. Even in the domain- specific KOS, enabling to determine what subject field the terms creating their vocabulary pertain to (such as AGROVOC covers issues of agriculture), this is not the same as determining the contents („aboutness“) in the standard professional texts (AGROVOC certainly is not about agriculture, DDC doubtlessly is not about Dewey decimal classification).
The problem of the NKOS AP application profile in its existing version consists in that it is difficult to determine some specific values – it seems to be anticipated that the data will be entered by the producers of KOS, but not those who process them, e.g. the librarians. Filling the elements of KOS description according to NKOS AP by a third party often requires basic investigation on the level of research description of museum or archive facilities. This aspect is nothing adverse in the case of the knowledge base being designed, some research activities being envisaged, but it would be problematic in the case of routine description. Even the seemingly unambiguous issue like date can cause problems– the moment of origin is often difficult to determine on the level of work and manifestation in case of electronic sources. In addition to that, due to the dynamic nature of KOS, not only the date of origin, but also information about changes is interesting, often even on the micro-level of single entries, which makes the number of data grow. In the case of date the following definition of the vocabulary DC-terms (dc:date) seems to be appropriate – „a certain point or period of time associated with an event in the lifecycle of the resource […] at any level of granularity“. However, the utilization of the potential of this definition will require the analysis and the description of the complicated life cycle of the knowledge organization systems. The KOS-specific elements appear to need created vocabularies (code lists), or at least very precise specifications of the contents of each given element, or else the consistence of entered data is threatened.
In spite of these partial problems we feel that the FRBR model, including the application profile NKOS AP based upon the same, has been successful in the task of the KOS description. Its potential to express relationships is seen as the strong side of the FRBR model. Down to the present day we have managed to enter all relationships established by the analysis of various KOS into the knowledge base, and namely by way of standardized types of relationships comprised in the specification of the model.
Concerning the future development of the knowledge base in its descriptive module, we consider the extent of explicity of description to be the key issue. Theoretically, it would be possible to sum up all properties that are specific for the knowledge organization systems in the free text of one descriptive element. At the present day our basis contains data implicitely integrated in the element bibliographic citation, and namely about the version (edition), about the copyright and about availability. The element description contains, in form of unstructured text, data about the history, frequency of updating, user determination, services offered, internal structure and external relations of the system. The advantage of unstructured free text resides in the possibility of expressing all specific aspects, some of them being unique for a certain KOS. Its disadvantage is difficult back-tracing of implicite data and the practical impossibility of quantitative analyses or filtering according to a given criterion etc. The pros and cons of structured data are opposite. Easy searching of structured data is accompanied with the necessity of very precise and uniform specification, which is usually possible only for the price of a certain generalisation and, accordingly, the loss of information about some unique and non-typical features of certain KOS. Even the seemingly unambiguous data about the scope/number of units of KOS requires exact definition of what is considered to be a unit. All terms or only the preferred ones? The main attributes or also the auxiliary ones? How do we proceed in case of facete structure?
The study has supplied a review of the past phases of solution of the knowledge base project in the field of knowledge organization, focusing upon the design of metadata description for KOS. It is positive that most “five-star” parameters of the descriptive elements have been achieved – as necessary for exposing them in the format of linked open data. The final, more or less administrative step will consist in assigning URIs to the descriptive elements, in order to be fully identifiable and technically linkable with semantically mapped data from other relevant name spaces.
The study is a partial solution output of the NAKI DF13P01OVV013 project Knowledge base for the field of information and knowledge organization, implemented by ÚISK FF UK in Prague
References
BRATKOVÁ, Eva, KUČEROVÁ, Helena. Systémy organizace znalostí a jejich typologie. In: Knihovna. 2014, 25(2), 5-29. ISSN 1801-3252 (Print). ISSN 1802-8772 (Online). Also available from: http://knihovna.nkp.cz/pdf/1402/142005.pdf. English version available from: http://knihovna.nkp.cz/pdf/1402sup/142001.pdf.
COYLE, Karen, BAKER, Thomas. Guidelines for Dublin Core Application Profiles [online]. Dublin (Ohio): DCMI, 2009-05-18 [cit. 2015-02-26]. Available from: http://dublincore.org/documents/profile-guidelines/.
Dublin Core Metadata Initiative. NKOS Task Group. NKOS AP Elements. In: DCMI NKOS Task Group [online]. 2013, updates 2014-04-03 final, polished 2014-08-03 [cit. 2015-02-26]. Available from: http://wiki.dublincore.org/index.php/NKOS_AP_Elements.
Dublin Core Metadata Initiative. NKOS Task Group. NKOS Vocabularies. In: DCMI NKOS Task Group [online]. 2013, updated 2013-12-16 [cit. 2015-02-26]. Available from: http://wiki.dublincore.org/index.php/NKOS_Vocabularies.
Dublin Core Metadata Initiative. NKOS Task Group. NKOS Vocabularies. 2., KOS Types Vocabulary. In: DCMI NKOS Task Group [online]. 2013, updated 2013-12-16 [cit. 2015-02-26]. Available from: http://wiki.dublincore.org/index.php/NKOS_Vocabularies#KOS_Types_Vocabulary.
FONS, Ted, PENKA, Jeff, WALLIS, Richard. OCLC’s Linked Data Initiative: Using Schema.org to Make Library Data Relevant on the Web. In: Information Standards Quarterly. Spring/Summer 2012, 24(2/3), 29-33. ISSN 1041-0031. Also available from: http://www.niso.org/apps/group_public/download.php/9408/IP_Fons-etal_OCLC_isqv24no2-3.pdf.
ISO 24156-1:2014. Graphic notations for concept modelling in terminology work and its relationship with UML -- Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014. 24 p.
PALMA, Raúl, HARTMANN, Jens, HAASE, Peter. OMV: Ontology Metadata Vocabulary for the Semantic web [online]. Version 2.4.1. S.l.: OMV Consortium, March 2009 [cit. 2015-02-28]. 76 s. OMV Report. Available from: http://sourceforge.net/projects/omv2/files/OMV%20Documentation/OMV-Reportv2.4.1.pdf.
World Web Consortium. Data catalog vocabulary (DCAT) [online]. W3C Recommendation 16 January 2014. Ed. Fadi MAALI, John ERICKSON. 2014-01-16 [cit. 2015-02-28]. Available from: http://www.w3.org/TR/vocab-dcat/.
[1] BRATKOVÁ, Eva, KUČEROVÁ, Helena. Systémy organizace znalostí a jejich typologie. In: Knihovna. 2014, 25(2), 5-29. ISSN 1801-3252 (Print). ISSN 1802-8772 (Online). Also available from: http://knihovna.nkp.cz/pdf/1402/142005.pdf. English version available from: http://knihovna.nkp.cz/pdf/1402sup/142001.pdf.
[2] Further KOS records entering continues also in 2015.
[3] For example, the identification of individual printed editions and versions of Danish Decimal Classification (Decimalklassedeling) was relatively successfuly solved through Danish National union catalogue of public libraries „bibliotek.dk“ in combination of the Royal Library catalogue.
[4] In VIAF database started appear the first permanent identifiers (VIAF ID) for works of some KOS, available is, for example, identifier (URI) for UDC (http://viaf.org/viaf/184301709/) or for LCC (http://viaf.org/viaf/203733980/), or also identifiers for expressions, for example identifier for Russian translation of UDC (http://viaf.org/viaf/185511525/) or identifier for Czech translation of selected UDC notations (http://viaf.org/viaf/186352368/).
[5] FONS, Ted, PENKA, Jeff, WALLIS, Richard. OCLC’s Linked Data Initiative: Using Schema.org to Make Library Data Relevant on the Web. In: Information Standards Quarterly. Spring/Summer 2012, 24(2/3), s. 29. ISSN 1041-0031. Also available from: http://www.niso.org/apps/group_public/download.php/9408/IP_Fons-etal_OCLC_isqv24no2-3.pdf.
[6] Metadata schema Schema.org was prepared in cooperation with Google, Bing, Yahoo and Yandex companies.
[7] The record of Dewey Decimal Classification in form of WebDewey database, presented in Fig. 2, is solved on level of subject description quite pragmatically: it is assigned by (and is linked) to „025.431“ notation (Dewey Decimal Classification) and also to FAST heading „Classification, Dewey decimal“. It is clear, that described classification scheme don’t deals “by itself”, and in this case it is not expression of subject content, but only formal name of KOS.
[8] Universitätsbibliothek Basel. BARTOC.org: BAsel Register of Thesauri, Ontologies & Classifications [online]. Projektleiter Andreas LEDL. Basel: Universitätsbibliothek Basel, 2013- [cit. 2015-02-25]. Freely available from Basel University server: http://www.bartoc.org/.
[9] BRATKOVÁ, Ref. no. 1, p. 19-20.
[10] The vocabulary is located in directory: http://www.bartoc.org/cs/taxonomy/term/.
[11] Access Innovations. TaxoBank Terminology Registry: TaxoBank [online]. Albuquerque (New Mexico, USA): ACCESS INNOVATIONS, 2009- [cit. 2015-02-25]. Available from: http://www.taxobank.org/.
[12] The typology of KOS and used terminology, see: BRATKOVÁ, Ref. no. 1, p. 18-19.
[13] Detailed record of NAL Thesaurus is on: http://www.taxobank.org/content/nal-agricultural-thesaurus.
[14] Name space for NKOS AP will be prepared on: http://purl.org/nkos/.
[15] Dublin Core Metadata Initiative. NKOS Task Group. NKOS AP Elements. In: DCMI NKOS Task Group [online]. 2013, updates 2014-04-03 final, polished 2014-08-03 [cit. 2015-02-26]. Available from: http://wiki.dublincore.org/index.php/NKOS_AP_Elements.
[16] Dublin Core Metadata Initiative. NKOS Task Group. NKOS Vocabularies. In: DCMI NKOS Task Group [online]. 2013, updated 2013-12-16 [cit. 2015-02-26]. Available from: http://wiki.dublincore.org/index.php/NKOS_Vocabularies.
[17] Presentaion of group and activity outcomes are available on its web: http://nkos.slis.kent.edu/.
[18] The database of ISTC identifiers manages the ISTC International Agency: http://www.istc-international.org/.
[19] Dublin Core Metadata Initiative. NKOS Task Group. NKOS Vocabularies. 2., KOS Types Vocabulary. In: DCMI NKOS Task Group [online]. 2013, updated 2013-12-16 [cit. 2015-02-26]. Available from: http://wiki.dublincore.org/index.php/NKOS_Vocabularies#KOS_Types_Vocabulary.
[20] COYLE, Karen, BAKER, Thomas. Guidelines for Dublin Core Application Profiles [online]. Dublin (Ohio): DCMI, 2009-05-18 [cit. 2015-02-26]. Available from: http://dublincore.org/documents/profile-guidelines/.
[21] Verbatim take of entity Thema from FRSAD model, which has not been translated into Czech to the time being.
[22] ISO 24156-1:2014. Graphic notations for concept modelling in terminology work and its relationship with UML -- Part 1: Guidelines for using UML notation in terminology work. 1st ed. Geneva: International Organization for Standardization, 2014. 24 p.
[23] Dublin Core Metadata Initiative. NKOS Task Group. NKOS Vocabularies, Ref. no. 15, http://wiki.dublincore.org/index.php/NKOS_Vocabularies.
[24] Dublin Core Metadata Initiative. NKOS Task Group. NKOS Vocabularies. 2., KOS Types Vocabulary, Ref. no. 18, http://wiki.dublincore.org/index.php/NKOS_Vocabularies#KOS_Types_Vocabulary.
[25] BRATKOVÁ, Ref. no. 1, p. 22. – In contradistinction to NKOS AP typology, which is linear list, our typology applies one level hierarchy.
[26] Classification System for Knowledge Organization Literature [online]. ISKO 2011-2012, last update 2012-04-13. Available from: http://www.isko.org/scheme.php.
[27] Library of Congress. MARC Code List for Relators [online]. Washington (D.C.): The Library of Congress, modified 2011-04-26 [cit. 2015-02-26]. Library of Congress Linked Data Service. Authorities and Vocabularies. Available from (URI): http://id.loc.gov/vocabulary/relators.
[28] BERNERS-LEE, Tim. Linked data – design issues [online]. 2006-07-27, last change 2009-06-18 [cit. 2015-04-10]. Available from: http://www.w3.org/DesignIssues/LinkedData.html.
[29] World Wide Web Consortium. Data catalog vocabulary (DCAT) [online]. W3C Recommendation 16 January 2014. Ed. Fadi MAALI, John ERICKSON. 2014-01-16 [cit. 2015-02-28]. Available from: http://www.w3.org/TR/vocab-dcat/.
[30] PALMA, Raúl, HARTMANN, Jens, HAASE, Peter. OMV: Ontology Metadata Vocabulary for the Semantic web [online]. Version 2.4.1. S.l.: OMV Consortium, March 2009 [cit. 2015-02-28]. 76 s. OMV Report. Available from: http://sourceforge.net/projects/omv2/files/OMV%20Documentation/OMV-Reportv2.4.1.pdf.
[31] See rich structure of defined relationships in Anthology vocabulary of relationships on: http://aims.fao.org/aos/agrontology.